Punchlines¶
Abstract
Pipelines are the best architectural and programming pattern for data centric applications. Machine learning, log management, stream processing, CEP are all built on top of pipelines. This short chapter explains how the punch helps you think, build and run pipeline using simple configuration files called punchlines.
Value Proposition¶
To go straight, the Punch helps you to invent useful processing pipelines.
You do that using only a configuration file called a punchline.

Some punchlines run best in the stream, i.e. continuously, while others run as batch. It all depends on the source and destination data sinks, and of course on the type of application you deal with. For example, a log parser runs in the stream, whereas a spark machine learning job might run as a periodic batch job. After all, it does not matter so much.
We could call these pipeline applications or jobs or extract-transform-load or .. there are many well-known excellent words. Punchlines is our term. Now pay attention to the following statement:
The Punch lets you design arbitrary punchlines using graphs through simple configuration files.
A unique format lets you design your graph using a library of ready-to-use nodes
(See reference guide for available punchline nodes types).
A node can be an input,
output or processing node. You can code your own and add them to the Punch.
Depending on what your punchline does, you will select the right target runtime environment.
The punch runtime is a lightweight stream processing runtime that, similarly to Storm runtime, is designed to run streaming pipeline.
These are traversed by the data, and you act on it in a number of ways.
In contrast, a Spark runtime is better suited to execute machine learning pipelines (stream or batch).
The key point is : because DAGs are very simple and generic,
you can define virtually every kind of useful applications. No need to code anything.
Execute a Punchline¶
Say you have a useful punchline. For example a stream processing application that you want to plugin between kafka and elasticsearch (that is one of the best-seller punchline). How do you run it ?
Start Simple ...¶
The Punch is quite original here. It is up to you to choose ! Why not start simple and execute your punchline in a single (unix) process, onto a single (unix) server. Something like this.
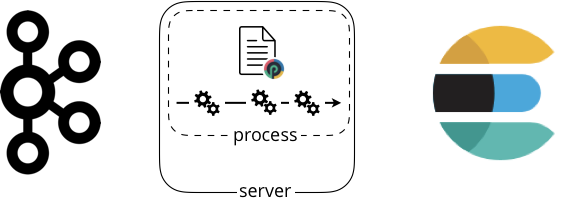
All you need to have is a linux server. If you need your pipeline to continuously run you can make it a cron, or a linux service, or rely on some systemd-like system. Nothing complex.
Does it scale enough ? Maybe not. You might need to add a more CPU power. How to do that ? The simplest solution is to request more instance of the function that is the bottleneck. For example:
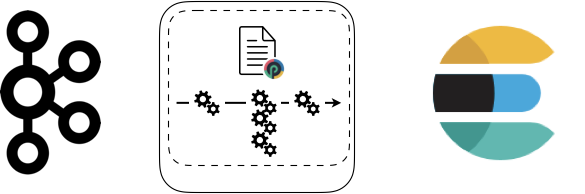
If you do that you still have a single process but more threads. That can be enough to do the job. Another solution consists in adding a server:
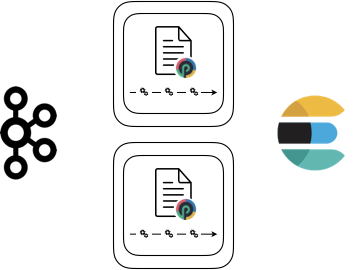
Wait ! there are some magic here: how will these two processes share the input load ? I.e. how will they consume the data from Kafka ? Short answer: the punchlines do that automatically. Just like Kafka Streams applications. Let us quote the benefits of such a simple approach from the kafka stream documentation:
Quote
- Elastic, highly scalable, fault-tolerant
- Deploy to containers, VMs, bare metal, cloud
- Equally viable for small, medium, & large use cases
- Write standard Java and Scala applications
- Exactly-once processing semantics
- No separate processing cluster required
To sum up, these examples simply require you have the servers, and something to execute processes. You can use physical linux boxes, virtual servers, docker, kubernetes.. it is up to you.
But Do Not Miss the Point¶
The previous examples are simple to understand, but do they make sense ? Yes if you have small apps dealing with a few thousands or events per second. Or only a few Gb of data to deal with using batch processing. If however you start processing lots of data (stream or batch) it is wise to benefit from more powerful runtime engines: Punch or Spark or even Storm.
If you take the same punchline and submit it to a (Storm|Spark) cluster instead of running in processes, here is what happens:
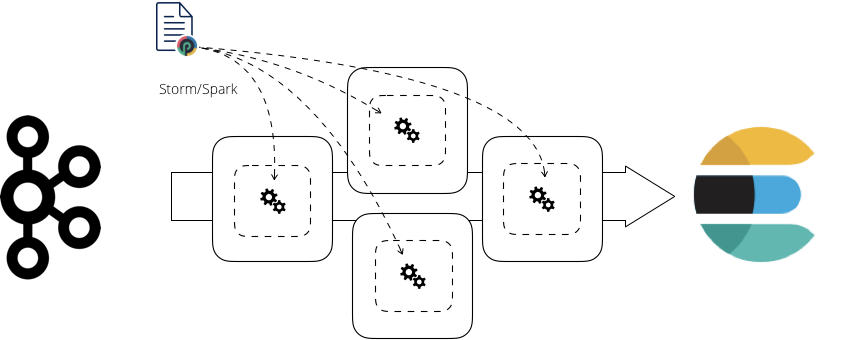
The sharding, distribution and data transport issues are all handled by and optimized by (Storm|Spark). It becomes much simpler and efficient to scale. Why simpler ? because you can ask (Storm|Spark) for more processes or threads. They will do the wiring for you.
Why is it more efficient ? Take the Spark use case: data are processed in there as DataFrame,
the whole pipeline is highly optimized by Spark before even be submitted. There are countless
good references on the web to understand this.
- databrick video on sql joins
- a focus on sql optimization
- Memory Cache and Code generation optimization
- etc ..
Why the Punch ?¶
Putting it all together, the Punch is quite unique. It is simple to understand, simple to learn and test, you can start small and end up big.
It helps you not spend lots of money and effort to try scalable pipelines, stream processing and machine learning platforms upfront. If you succeed on a simple setup, you are ready to go production.