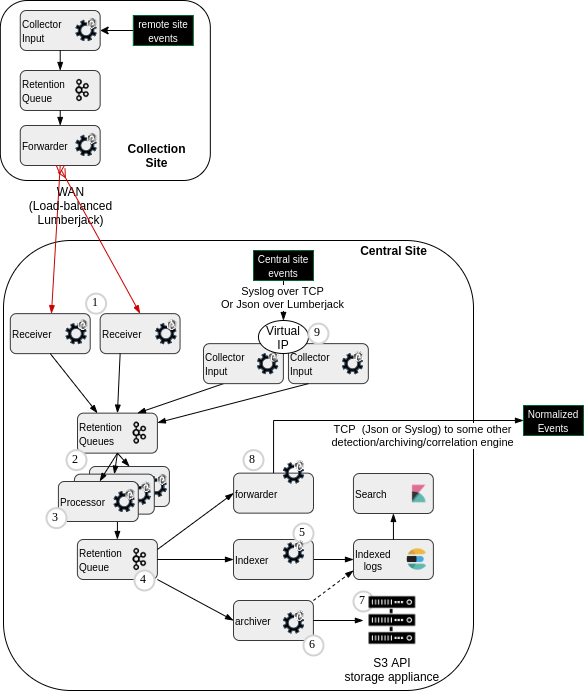
Central Log Management Reference Architecture: Archiver Punchlines (6)¶
Note
click on this link to go to Central Log Management reference architecture overview
Key design highlights¶
Two outputs: archive file + metadata¶
An archive is useless if we cannot use it. Most frequent usage are :
- mass export through filesystem tools (e.g.
cp -r). - targeted extraction of files for re-indexing/investigation purpose (or for completing/restoring indexing backend content during incident management).
- text pattern search in archive files to extract only probable matching events for re-indexing/investigation.
For the two latest, and for capacity planning purposes, an efficient indexing of the files contained in the archive is needed.
This is why the archiver node (actually a file_output node) is also producing JSON Metadata Records describing each stored archive file.
Sorting by tags¶
The file_output node allows to build separate files for logs that have different tags values.
The tags fields being a custom choice (usually: the log type/technology, the emitting datacenter, the users community...).
This means the tags values have to be computed at log processing time, and provided as additional fields in the log tuples stream.
RAM vs Streaming vs Replay complexity¶
Batches can take a long time to be filled. We want to build big files for efficient usage of the filesystem and for fast mass-extraction.
Because we do not want to need too much RAM to accumulate logs, log files are actually written as streams to the target storage (except for S3 object storage). This means the punchline has to acknowledge part of the logs (to flush them out of the tracking tables) BEFORE the files are finished (in fact all the logs except the first in the batch).
This makes it quite complicated in case of a filesystem or storage backend communication failure, to determine what needs to be replayed (because at the same time, other batches may have succeeded, with another part of the logs).
This is why, in case of batch failure, we configure the archiver punchline to die and restart at the last known "persisted offset" in the source Kafka. This also means that we cannot mix in a same batch file logs that have been read from distinct Kafka topic partitions. The File node takes care of this, by using the input partition id as yet one more "sorting tag"
Errors management¶
Unparsed logs (processing errors or exception) often have to be preserved as preciously as parsed logs (for legal reasons, or for later reprocessing after fixing the processing chain).
For this reason there is need of a punchline dedicated to archiving the errors.
NFS Mount point and storage 'root' not auto-creating¶
When the storage backend is a NFS device, mounted on all potential archiver servers, there is a risk when the NFS is for some reason not currently mounted. A writer application could write to the LOCAL filesystem (often, the operating system root filesystem), filling it up with un-centralized data that can endanger the operating system availability.
In addition, these unwanted local data may be 'hidden' under the actual mounted device, once the NFS system is back online, making it difficult to understand why the storage size has been exhausted on the root filesystem, and where the 'archived' data has gone.
For avoiding this, the good pattern is to never write at the root of a NFS mount, but always in an EXPECTED sub-folder. The absence of this sub-folder means that the NFS is not currently mounted, and therefore no write should be attempted.
This pattern can be implemented with the file_output node by providing it a storage address which is a pre-created folder inside the target filesystem, and requesting the file_output node to NOT CREATE this folder if it does not exist.
In addition, remember that the same storage mount point should be used on all archiver nodes, so that whatever the used nodes, the data will end up in the same filesystem, and will therefore be easy to locate using the metadata later.
Choice of archived fields: raw log vs parsed log vs both¶
Of course the raw log takes less place (2 to 3 times), and we often NEED to archive it for legal reasons. But keeping only this raw log means we will need to parse the log again if we want to extract it from the archive towards the indexing backend (Elasticsearch). For mass extraction/indexation this may imply a huge amount of cpu and computation time.
For this reason, keeping ALSO the parsed log is often advisable.
Note also that it is always a good idea to keep the unique log id (for deduplication purpose during replays: it can help restore seamlessly missing time ranges in the indexed backend, caused by production incidents that prevented normal indexing.
Parsed logs archiver Punchline example¶
Here is an example of a shared multi-log-technologies archiving punchline, where the index name has been pre-computed by the processor punchline.
version: "6.0"
tenant: reftenant
channel: archiver
runtime: shiva
type: punchline
name: logs_archiver
dag:
# Kafka input
- type: kafka_input
component: kafka_back_input_logs
settings:
topic: processor-logs-output
start_offset_strategy: last_committed
publish:
- stream: logs
fields:
- _ppf_id
- _ppf_timestamp
- log
- raw_log
- device_type
- subsystem
- _ppf_partition_id
- _ppf_partition_offset
- stream: _ppf_metrics
fields:
- _ppf_latency
# Archive logs in csv format
- type: file_output
component: file_output_logs
settings:
strategy: at_least_once
destination: file:///tmp/storage-dir
create_root: true
timestamp_field: _ppf_timestamp
file_prefix_pattern: "%{tag:subsystem}/%{tag:device_type}/%{date}/%{offset}"
encoding: csv
separator: _|_
compression_format: GZIP
batch_size: 750
batch_life_timeout: 1m
fields:
- _ppf_id
- _ppf_timestamp
- log
- raw_log
tags:
- subsystem
- device_type
executors: 1
subscribe:
- component: kafka_back_input_logs
stream: logs
- component: kafka_back_input_logs
stream: _ppf_metrics
publish:
- stream: metadatas
fields:
- metadata
- stream: _ppf_metrics
fields:
- _ppf_latency
# The `elasticsearch_output` produces `_ppf_errors` if metadatas indexation fails.
# It prevents previous `file_output` from blocking if no ack is received from `elasticsearch_output`.
- type: elasticsearch_output
component: elasticsearch_output_metadatas
settings:
cluster_id: es_data
unavailability_failure_action: forward
bulk_failure_action: forward
reindex_failed_documents: false
per_stream_settings:
- stream: metadatas
index:
type: daily
prefix: reftenant-archive-
document_json_field: metadata
batch_size: 1
error_index:
type: daily
prefix: reftenant-indexing-errors-archive-
subscribe:
- component: file_output_logs
stream: metadatas
- component: file_output_logs
stream: _ppf_metrics
publish:
- stream: _ppf_errors
fields:
- _ppf_error_document
- stream: _ppf_metrics
fields:
- _ppf_latency
# The `kafka_output` saves failed metadatas from `elasticsearch_output`.
- type: kafka_output
component: kafka_back_output_metadatas
settings:
topic: archiver-metadata
encoding: lumberjack
producer.acks: "1"
subscribe:
- stream: _ppf_errors
component: elasticsearch_output_metadatas
- stream: _ppf_metrics
component: elasticsearch_output_metadatas
metrics:
reporters:
- type: kafka
reporting_interval: 60
settings:
topology.max.spout.pending: 500
topology.component.resources.onheap.memory.mb: 100
topology.enable.message.timeouts: true
topology.message.timeout.secs: 600
Processing errors archiver Punchline example¶
Here is an example of the special case 'processing errors' archiver punchline.
Please refer to Processing errors indexing or inlined comments for some explanations.
version: "6.0"
tenant: reftenant
channel: archiver
runtime: shiva
type: punchline
name: errors_archiver
dag:
# Kafka input Switch errors
- type: kafka_input
component: kafka_front_input_switch_errors
settings:
topic: reftenant-receiver-switch-errors
start_offset_strategy: last_committed
publish:
- stream: errors
fields:
- _ppf_id
- _ppf_timestamp
- _ppf_error_document
- subsystem
- _ppf_partition_id
- _ppf_partition_offset
- stream: _ppf_metrics
fields:
- _ppf_latency
# Kafka input process errors
- type: kafka_input
component: kafka_back_input_process_errors
settings:
topic: processor-errors-output
start_offset_strategy: last_committed
publish:
- stream: errors
fields:
- _ppf_id
- _ppf_timestamp
- _ppf_error_document
- subsystem
- device_type
- _ppf_partition_id
- _ppf_partition_offset
- stream: _ppf_metrics
fields:
- _ppf_latency
# File output switch errors
- type: file_output
component: file_output_switch_errors
settings:
strategy: at_least_once
destination: file:///tmp/storage-dir
create_root: true
timestamp_field: _ppf_timestamp
file_prefix_pattern: "%{tag:subsystem}/errors/central/%{topic}/%{date}/%{offset}"
encoding: csv
compression_format: GZIP
batch_size: 750
batch_life_timeout: 1m
fields:
- _ppf_id
- _ppf_timestamp
- _ppf_error_document
tags:
- subsystem
executors: 1
subscribe:
- component: kafka_front_input_switch_errors
stream: errors
- component: kafka_front_input_switch_errors
stream: _ppf_metrics
publish:
- stream: metadatas
fields:
- metadata
- stream: _ppf_metrics
fields:
- _ppf_latency
# File Output process errors
- type: file_output
component: file_output_process_errors
settings:
strategy: at_least_once
destination: file:///tmp/storage-dir
create_root: true
timestamp_field: _ppf_timestamp
file_prefix_pattern: "%{tag:subsystem}/%{tag:device_type}/errors/%{date}/%{offset}"
encoding: csv
compression_format: GZIP
batch_size: 750
batch_life_timeout: 1m
fields:
- _ppf_id
- _ppf_timestamp
- _ppf_error_document
tags:
- subsystem
- device_type
executors: 1
subscribe:
- component: kafka_back_input_process_errors
stream: errors
- component: kafka_back_input_process_errors
stream: _ppf_metrics
publish:
- stream: metadatas
fields:
- metadata
- stream: _ppf_metrics
fields:
- _ppf_latency
# The `elasticsearch_output` produces `_ppf_errors` if metadatas indexation fails.
# It prevents previous `file_output` from blocking if no ack is received from `elasticsearch_output`.
- type: elasticsearch_output
component: elasticsearch_output_metadatas
settings:
cluster_id: es_data
per_stream_settings:
- stream: metadatas
index:
type: daily
prefix: reftenant-archive-errors-
document_json_field: metadata
batch_size: 1
bulk_failure_action: forward
reindex_failed_documents: true
reindex_only_mapping_exceptions: true
error_index:
type: daily
prefix: reftenant-indexing-errors-archive-errors-
subscribe:
- component: file_output_switch_errors
stream: metadatas
- component: file_output_switch_errors
stream: _ppf_metrics
- component: file_output_process_errors
stream: metadatas
- component: file_output_process_errors
stream: _ppf_metrics
publish:
- stream: _ppf_errors
fields:
- _ppf_error_document
- stream: _ppf_metrics
fields:
- _ppf_latency
# The `kafka_output` saves failed metadatas from `elasticsearch_output`.
- type: kafka_output
component: kafka_back_output_metadatas
settings:
topic: archiver-metadata
encoding: lumberjack
producer.acks: "1"
subscribe:
- stream: _ppf_errors
component: elasticsearch_output_metadatas
- stream: _ppf_metrics
component: elasticsearch_output_metadatas
metrics:
reporters:
- type: kafka
reporting_interval: 60
settings:
topology.max.spout.pending: 500
topology.component.resources.onheap.memory.mb: 100
topology.enable.message.timeouts: true
topology.message.timeout.secs: 600