Elasticsearch Output¶
The ElasticSearchOutput receives Storm tuples, convert them in a Json document and write that document to ElasticSearch. It supports both SSL and/or basic authentication.
To get the best performance yet benefit from reliability, this node uses a bulked asynchronous strategy. Messages are batched by small groups (1000 by default). This said tuples are acked only after being acked by elasticsearch, so that your topologies are guaranteed to process all the incoming tuples.
Tip
make sure you understand the stream and field punchplatform concepts. These are explained in details in the inputs and nodes javadocs.
Overview¶
The data arrives at the ElasticsearchOutput as part of stream(s) of key value fields. Some of these fields are payload data (i.e. the ones you want to insert into Elasticsearch), others are metadata (unique ids, timestamp, index hints etc ...).
Consider the next example, on the stream logs, you receive
two keys : log and _ppf_id.
logs => [ "log": { "name": "alice", "age": 23}, "_ppf_id": "12asyw" ]
This example is typical of a log management configuration, where one of
the field (here log) actually contains the Json document
to insert, the other field contains a unique identifier to be used as
document's unique identifier inside Elasticsearch (to avoid duplication of logs in case of replay).
Say you want to insert in Elasticsearch the following document:
# document ID: "12asyw"
{
"@timestamp": "2018-05-24T13:47:32.642Z",
"name": "alice",
"age": 23
}
i.e. use 12asyw as document identifier, and add an iso
@timestamp field. The settings to achieve this is
illustrated next :
{
type: elasticsearch_output
settings: {
cluster_id: es_search
per_stream_settings : [
# each subscribed stream must have a settings section
{
# this section only applies for tuples received on stream "logs"
stream : logs
# send the document to a daily index with a given prefix (Note that "monthly" and "yearly" can also be used to reduce ES Cluster cluttering with small indices)
index : {
type : daily
prefix : mytenant-events-
}
# take a given input tuple field as json document.
# there can be only one such a field.
document_json_field : log
# use another field (_ppf_id) as unique id for inserting that document to lasticsearch
document_id_field : _ppf_id
# in addition to the 'log' field, add a '@timestamp' field with the current time.
additional_document_value_fields : [
{
type : date
document_field : @timestamp
format : iso
}
]
}
]
}
subscribe: [
{
component: punchlet_node
stream: logs
}
]
}
Warning
The above simple example may not be suitable for production need, if you do not want to risk losing unprocessed tuples in some error cases (see reindex_failed_documents settings and Indexing Error Handling section ).
In the rest of this chapter we describe how you can finely control the various metadata : index name, ids, timestamps, and additional fields.
Global Parameters¶
The elasticsearch output accepts the following settings:
-
cluster_id: (string, mandatory)the name of the elasticsearch cluster
-
batch_size: (integer: 1000)the size of the bulk written at once to elasticsearch.
-
batch_interval(integer: 1000)In milliseconds. When the traffic is low, data is flushed regularly. Use this interval to set the flush period. Note that if the value is large, you will suffer from a delay.
-
request_timeout(string: "20s")The Elasticsearch output sends bulk indexation requests as soon as the batch_size is reached (or batch is older than batch_interval). If your topology max_spout_pending is big enough, multiple batches requests may be started at close interval ; of course, when Elasticsearch is loaded, the last submitted request may have to wait for the previous one to complete before being actually executed, leading to longer wait time for the HTTP Response. If you want to avoid Storm tuple failures due to this timeout, please increase your request timeout in relationship with the number of concurrent batches that allows your max_spout_pending/batch_size ratio.
-
reindex_failed_documents(boolean: false)When an Elasticsearch output tries to insert a document into Elasticsearch and gets a rejection from Elasticsearch, we may want to keep track of this event (including the faulty document) and record it somewhere else in Elasticsearch. This can be done by putting this setting value to true AND by providing
error_indexsetting. See alsoreindex_only_mapping_exceptionsandfail_tuples_if_an_insertion_of_error_document_is_not_donesettings. -
reindex_only_mapping_exceptions(boolean: false)A document insertion can fail due to numerous causes. The main one being a mapping issue, we may only want to keep track of this kind of document failure.
-
error_index(dictionary)Control the error index into which records will be inserted to keep track of failure to index documents in Elasticsearch. The faulty document will be (escaped) inside the error record. This setting is ignored if 'reindex_failed_documents' is set to false or missing. cf target_index definition for dictionary examples.
-
fail_tuples_if_an_insertion_of_error_document_is_not_done(boolean: true)When trying to insert the error document, a new failure may occur. If this happens, the document is forwarded, or failed if no error stream is configured. You can bypass this behaviour by setting this parameter to false. The failed error log will therefore be acked. WARNING : this can obviously lead to log loss. Use with care.
When the default (false) value is used, then an error is recorded in logs of the Storm topology, and the faulty document is not inserted at all, and lost.
-
bulk_failure_action(string: forward)When a whole bulk request fails while trying to insert into Elasticsearch due to a malformed request, the default behaviour is try to forward the tuples to the stream configured in
bulk_failure_stream. If there's no such stream, all the tuple are failed. In production, we may want to avoid that, because it could flood the error stream. This parameter allows 3 values : forward (default), ack and fail. Ack will simply ack the tuples, i.e. ignore them, and fail will fail the tuples so that they can be processed again later. -
bulk_failure_stream(string: _ppf_errors)The stream to use when forwarding a document after a bulk failure. Default to _ppf_errors.
-
unavailability_failure_action(string: fail)When a whole bulk request fails while trying to insert into Elasticsearch due to a cluster unavailability, the default behaviour is to fail all the tuples of the bulk and let the input node of the punchline to emit the tuples again. In some case we may want to avoid that (for instance to avoid slowing down the archiving process because metadata cannot be indexed). This parameter allows 3 values : forward, ack and fail (default). Ack will simply ack the tuples, i.e. ignore them. Fail will fail the tuples so that they can be processed again later. At least forward will forward the tuples to an "unavailability_failure_stream"
-
unavailability_failure_stream(string: _ppf_errors)The stream to use when forwarding a document after an unavailability failure. Default to _ppf_errors.
Watch out : not publishing bulk or unavailability stream will make elasticsearch insertion errors result in failing tuples.
Watch out : The fail action associated to an unacknowledged input node (such as syslog input node) can leads to tuples loss.
-
per_stream_settings(dictionary)Each subscribed stream must have a dedicated settings dictionary. Refer to the documentation hereafter.
-
credentialsIf you need basic auth, use a credentials dictionary to provide the user password to use. For example :
"credentials" : { "user" : bob, "password" : "bob's password" }These settings can be combined with ssl. token parameter can be specified like that:
"credentials": { "token": "mytoken", "token_type": "ApiKey" }. Note, if user and password are specified, they will be ignored in favor of token parameter. Token are the base64 encoded string "user:password" if set to type: Basic
Target Index¶
To control the target index name, use the (per stream) property:
# insert into a daily index. You must provide the prefix.
# Note that your also can use 'monthly' or 'yearly' if your index content is intended to be small, to avoid Elasticsearch cluster cluttering with too many indices to manage.
index : {
type : daily
prefix : some_prefix_
}
# insert into an index provided by one of the subscribed field.
index : {
type : tuple_field
tuple_field : index_name
}
# insert into a fixed named index
index : {
type : constant
value : constant_index_name
}
Target Type¶
To control the elastic search type where the document are written, use the (per stream) property:
# insert into an index with the type mytype, the default value is _doc.
document_type: mytype
Warning
Type mapping are deprecated since ElasticSearch 7. Therefore, this parameter is optional and should be used only when dealing with an Elasticsearch version prior to the 7th.
Additional fields¶
Additional fields allows you to add data to your elasticsearch document. Typically, a timestamp. Here are the possibilities:
additional_document_value_fields : [
# insert a generated timestamp
{
type : date
document_field : @timestamp
format : iso
}
# insert a timestamp provided by one of the received input tuple field.
# This requires the corresponding field to contain a unix timestamp representation.
# Typically the one generated by the punchplatform spouts
{
type : date
tuple_field : _ppf_timestamp
document_field : @timestamp
format : iso
}
# insert on of the input tuple field as plain leaf value.
# This requires the corresponding field to contain a string, long,
# boolean, or double value.
{
type : tuple_field
tuple_field : _ppf_channel
document_field : channel
}
# insert a constant additional field
index : {
type : constant
value : banana
document_field : fruit
}
]
Punch Error Document Handling¶
If you have punchlet(s) in your channels, they can generate error documents in case the punchlet(s) fail.
These are emitted just like other document, with a different content. If you want to save these errors in Elasticsearch (you should !) you simply must configure your node to properly deal with the error stream.
{
type : elasticsearch_output
settings : {
per_stream_settings : [
{
stream : _ppf_errors
document_value_fields : [
_ppf_error_message
_ppf_error_document
_ppf_timestamp
]
index : { ... }
document_id_field : _ppf_id
additional_document_value_fields : [ ... ]
}
...
]
}
subscribe: [
{
component: some_spout
stream: _ppf_errors
}
]
}
Remember the reserved content of the punchplatform fields (refer to reserved fields) in particular :
- _ppf_error_document : contains the input document that generated the error.
- _ppf_error_message : contains a useful error message including the punchlet error line where the error was raised.
It is worth noticing that:
- the timestamp property as just illustrated makes the node generate a timestamp value based on the current time. Do not be confused with a business timestamp that might be present in your input document.
- the index property in this example will generate an index based on the current day.
Security¶
Additional parameters are available to configure the Elasticsearch output node with security settings for :
- TLS : using keystores or key files
- Authentication : using credentials with a basic user and password or a token
Example :
{
type: elasticsearch_output
settings: {
cluster_id: es_search
http_hosts: [
{
host: localhost
port: 9200
}
]
credentials: {
user: bob
password: bob_secret
}
ssl: true
ssl_keystore_location: /data/certs/keystore.jks
ssl_truststore_location: data/certs/truststore.jks
ssl_keystore_pass: keystore_secret
ssl_truststore_pass: truststore_secret
per_stream_settings: [
...
]
}
}
-
credentials.user: (string)Username used by th Elasticsearch output node to authenticate to the Elasticsearch cluster. If provided,
credentials.passwordMUST be configured. Cannot work withcredentials.tokenandcredentials.token_type. -
credentials.password: (string)Username used by th Elasticsearch output node to authenticate to the Elasticsearch cluster. If provided,
credentials.userMUST be configured. Cannot work withcredentials.tokenandcredentials.token_type. -
credentials.token: (string)Token string used by th Elasticsearch output node to authenticate to the Elasticsearch cluster. If provided,
credentials.token_typeMUST be configured. Cannot work withcredentials.userandcredentials.password. -
credentials.token_type: (string)Token type used by th Elasticsearch output node to authenticate to the Elasticsearch cluster. If provided,
credentials.tokenMUST be configured. Cannot work withcredentials.userandcredentials.password. UseBasicfor a base64 encoded token string for authentication,Bearerfor tokens based on the OAuth2 specs, orApiKeyfor custom api key generation.Check Token-based authentication services Elasticsearch's documentation for more information.
-
ssl: (boolean: false)Enable TLS encryption over the Elasticsearch output node's connexion to the Elasticsearch cluster. If
false, all the following configurations are ignored.
Warning
For SSL files, use key files OR keystores settings, but not both
-
ssl_private_key: (string)Path to the
PKCS8private key of the Elasticsearch output node. -
ssl_certificate: (string)Path to the
x509public key of the Elasticsearch output node. This certificate should always be generated with at least theusr_certextension as itsx509v3extended usage for client purpose. -
ssl_trusted_certificate: (string)Path to the CA file containing the trusted certificates by the Elasticsearch output node. It should also contain its own CA root and all the intermediate certificates if this one is not self-signed.
-
ssl_keystore_location: (string)Path to the keystore containing the Elasticsearch output node's public and private keys.
jks,pkcs12andp12keystore types are supported. -
ssl_keystore_pass: (string)Password of the keystore provided with
ssl_keystore_location. Do not provide this configuration if no password protects the keystore. -
ssl_truststore_location: (string)Path to the truststore containing the Elasticsearch output node's CA file and all the certificates trusted by this node.
jks,pkcs12andp12truststore types are supported. -
ssl_truststore_pass: (string)Password of the truststore provided with
ssl_truststore_location. Do not provide this configuration if no password protects the truststore. -
ssl_hostname_verification(boolean: true)Whether the node client should resolve the nodes hostnames to IP addresses or not.
Idempotency and replay¶
You can configure your node in various ways but pay attention to two important fields :
- the _ppf_id lets you insert documents with a deterministic identifier. If you replay your data (by reading again a Kafka queue), it will replace existing documents in elasticsearch documents. This is likely something you want to replay and enrich existing documents.
- the _ppf_timestamp lets you use the punchplatform entry time as timestamp. Again should you replay your data, that timestamp will always correspond to that entry time.
Elasticsearch Indexing Error Handling¶
This chapter explains how you deal with this without loosing any data.
An inserted document can be refused by Elasticsearch, because of three main causes:
-
the entire bulk request is rejected because of a malformed bulk json (the request fails at client side) These errors are managed by the following settings: bulk_failure_action, bulk_failure_stream
-
the entire bulk request is rejected mainly because the cluster is unavailable or overloaded (the request fails at client side). These errors are managed by the following settings: unavailability_failure_action, unavailability_failure_stream
-
A single document inside the bulk is rejected mainly because of a mapping exception or other errors (elasticsearch provide an answer). These errors are managed by the following settings: reindex_only_mapping_exceptions, error_index, fail_tuples_if_an_insertion_of_error_document_is_not_done
The error handling follows this diagram :
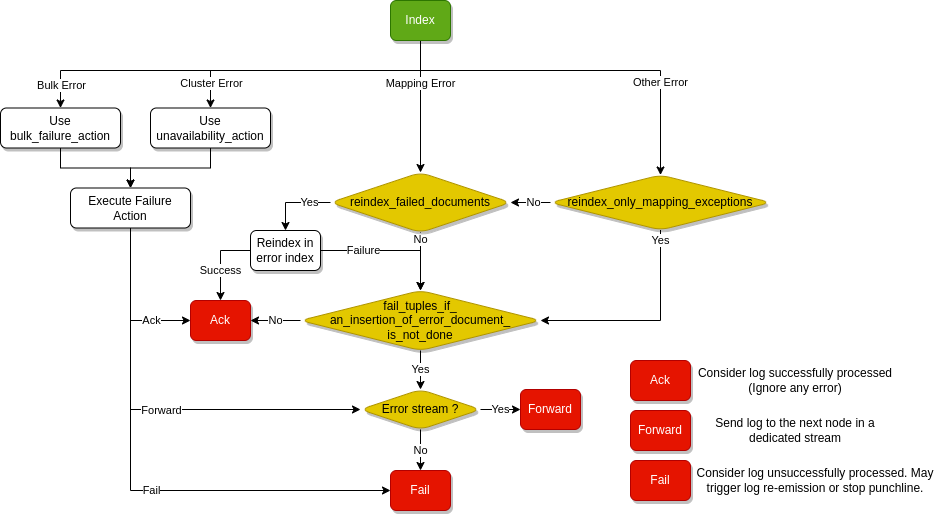
Single document reindexation¶
Activated by the reindex_failed_documents setting, the insertion errors of a single documents will be converted to "error documents"
and inserted into Elasticsearch in a more safe way inside the index define by error_index (see following paragraphs).
By default, reindex applies to every document of a successfull bulk whatever the reason of the indexation error. However,
you can limit this behaviour only to apply on mapping/field-type exception with the reindex_only_mapping_exceptions settings.
In this case, other errors are sent to _ppf_errors stream if the node publishes it or failed otherwise.
{
type: elasticsearch_output
settings: {
cluster_id: es_search
reindex_failed_documents: true
reindex_only_mapping_exceptions: true
error_index: {
type: daily
prefix: mytenant-events-indexation-errors-
}
per_stream_settings: [
...
]
}
}
Error Document content¶
The node will generate an error document based on the input tuple fields
plus a timestamp (@timestamp by default). The rule is simple :
- regular user fields : the content of these are escaped and put as json string property. The key is the corresponding key field.
- punch reserved fields (i.e. starting with
_ppf) : the content of these are put as is as json (string or numerical) property. The key is also the corresponding key field.
Here is an example : say you receive this tuple:
[ "log": { "age": 23 , "ip": "not a valid ip" }, "_ppf_id": "12asyw" ]
Expecting the "log" field to hold the document to insert to elasticsearch. The node first attempt to write this into elasticsearch :
{ "age" : 23 , "ip" : "not a valid ip" }
It fails because, in this case, the field ip does not
contains a valid ip address. The node will then insert into the specified error
index the following document:
{
"@timestamp" : "2018-05-24T13:47:32.642Z",
"_ppf_id": "12asyw",
"log" : "{\"age\": 23 , \"ip\": \"not a valid ip\" }"
}
This time the document will be accepted (as long as the error index mapping is properly defined of course).
Escaping strategy¶
To ensure error document will not be themselves refused, any user field is escaped (i.e. transformed in a plain string with all quotes and reserved json characters escaped). In contrast, reserved punchplatform fields (refer to IReservedFields) will be included as is. These can only contain safe strings with no risk to being refused by elasticsearch.
Rationale¶
Dealing with errors without loosing data is a complex issue. The punchplatform design ensures you can manage the different use case you want.
prioritize indexing without loss (default behaviour)¶
-
unavailability_failure_action : "fail" so we wait the cluster to be up to move forward
-
bulk_failure_action : "forward" to "_ppf_errors" so the failing bulk does not block the indexing chain
-
reindex_failed_document: true to ensure all single document is inserted with all the required field to understand the error cause.
prioritize non blocking process (indexing archive's metadatas)¶
- unavailability/bulk_failure_action : "forward" to "_ppf_errors" so the archiving process is not block if the cluster is unavailable and forwarded document can be managed later by another punchline.
- reindex_failed_document: false