Exception Handling¶
An exception can be explicitly raised with a throw declaration
throw new PunchRuntimeException("mymessage");
You can also simply write :
raise("mymessage");
Sometimes a PunchRuntimeException is implicitly raised, should you encounter unexpected error: null pointer, wrong format, type error, ...
When an exception is raised, the normal execution of the punchlet is interrupted. You can try it using small punchlet example. On a real platform handling exception properly is crucial in order to:
- not loose the input data should it suffer from a runtime error
- add useful context data to the error message content
- forward that error message to a configured back-end (kafka, elasticsearch, archiving...) so as to be able reprocess it.
When your punchlet is run in a Storm pipeline (as part of the PunchPlatform Storm PunchBolt), the workflow is more complex. The rest of this chapter explains this. It is key to understand how you can deal with production errors without loosing data.
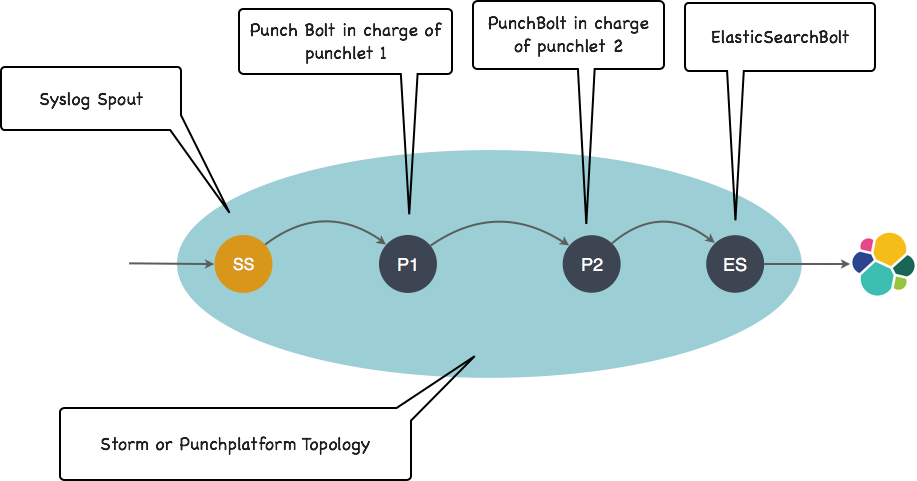
Here is how it works explained on a simple example. Consider a topology made of one spout, and three bolts: 2 processing bolts (running punchlets) and one output bolt to Elasticsearch. It is illustrated next :
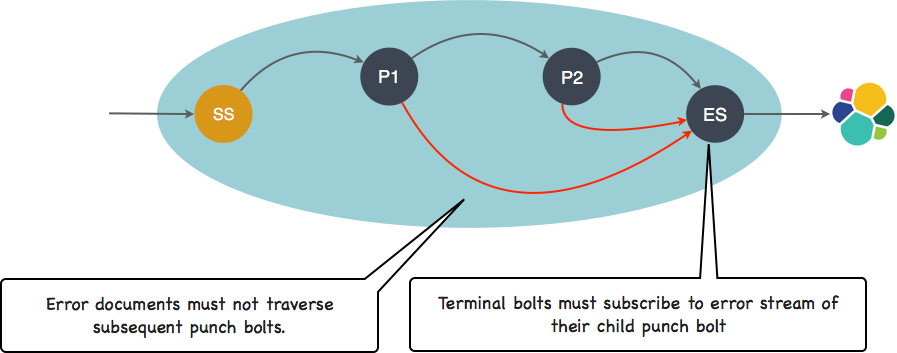
Let us now configure thi graph to also deal with error propagation. Errors raised by punchlets are emitted on a reserved stream ([_ppf_errors]). All you have to do is to define the path to forward these errors to where they should be processed. Coming back to our example, the red path is the one you need so that errors do not traverse subsequent punchlets but go straight to a terminal bolt to be (in this example) indexed and saved to elasticsearch.
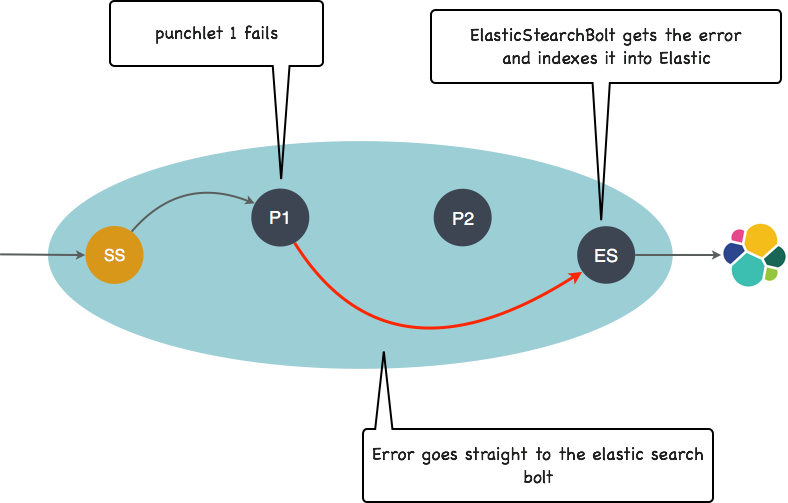
With this mechanism, you have a lot of control to deal with your runtime errors. Coming back to our example, here is what happens should the first punchlet raise an exception.
End-to-end exception handling is a more sophisticated feature than just explained. In particular the scheme just illustrated works across several topologies/kafka topics.
The exception handling workflow is, in a nutshell, the following:
- when the exception occurs, the PunchBolt stores the input data together with the error cause and location in an error Tuple.
- The error Tuple is emitted to a reserved stream, it is your responsibility to do something useful with it : save it to archiving, to kafka, to elasticsearch.
- In a distributed setup, errors generated by an upfront topology might need to be forwarded by downstream topologies to ultimately reach the right backend. The PunchPlatform lets you do that easily by simply configuring the graph to properly handle the error stream.