Deployment Process¶
The punch is not a monolithic platform that comes with an all-or-nothing logic. For the sake of clarity let us first identoify the several types of deployments.
- Complete deployments : you have only servers, virtual or bare. In that case you deploy a complete punch that includes all the required components at play : kafka elasticsearch etc ..
- Partial deployments : you already have some service up and running. Say Elasticsearch an Kafka. You then deploy only the punch additional modules and/or the punch embedded COTS you need. It does not differ from a complete deployment, you simply select only a subset of your components.
- Container based deployments : if you have a container runtime environment such as kubernetes, you can deploy some of the punch applications directly using containers.
In the resst of this chapter we provide high level information for you to grasp the overall logic of a complete deployment.
How It Works¶
Deploying a whole punchplatform-based system implies 3 levels of deployment:
-
Deploying your infrastructure (networking and firewalling, physical and virtual servers, storage devices...) and solution-specific operating system level settings (partitioning and mount points, networking, security/hardening, time alignement, auditing...).
For this part, the punchplatform product provides no automation tool, as Punch is quite agnostic about some infrastruture choices (virtualized or not, multiple supported OS and OS versions, in the cloud or in containers...)
-
Deploying the Punch software framework components (Open sources and specific Punch components) needed for supporting your applications/solution.
-
Deploying solution-specific runtime platform configuration (elastic settings, opendistro LDAP binding...) and pipelines/applications/analytics configuration inside this aframework of components.
At minimum, to deploy a punch you need:
- a laptop or server to act as 'the deployer',
- the target servers (physical or virtual ones) where you want to deploy your platform components and configuration,
- and an access to standard packages repositories associated to your operating system version.
The starting situation is illustrated next.
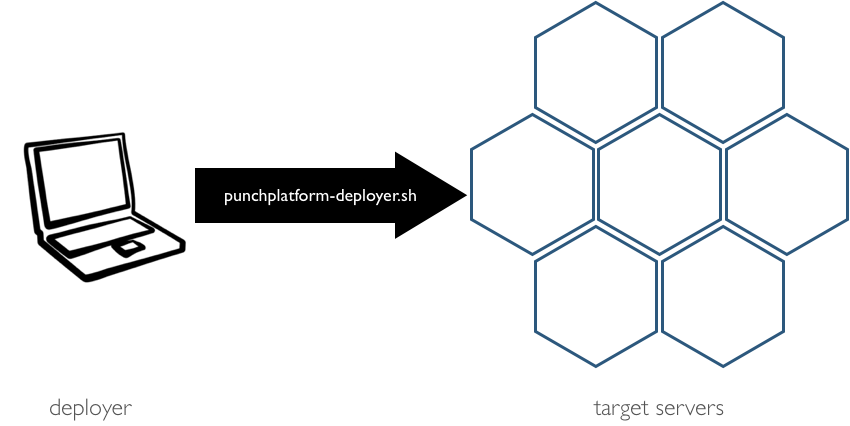
The punchplatform-deployer.sh tool is a punchplatform software tool delivered as part of the
installation package of the Punchplatform framework.
All you have to provide to use it is a description of your target platform. I.e. what component you want to deploy on what server. That description is up to you to define (system engineering phase). In short you must provide a punchplatform-deployment.settings json file.
Once you have that deployment file, running the tool is easy and fully automated.
Deployment Steps¶
The deployment procedure is composed of successive different steps :
- Install prerequisites on deployer & targets servers
- Create or import your configuration files for deployment : punchplatform-deployment.settings & resolv.hjson
- Deploy your platform software components and daemons
- Configure your platform with runtime resources and business logic
Configuration Management¶
It is important to understand the punch configuration logic, and how users interact with the platform.
There are two very different types of users :
-
operators work using command line tools and have permissions to alter through this environment the configuration of applications running inside the Punch framework, to start, stop or reload channels that include these applications.
These operators are administrators and advanced users. In addition, some of these operators are also able to start/stop/restart punchplatform and open-source framework daemons. These are the platform administrators, with sudoers rights. Punch operators that do not have sudoers rights are sometimes called 'application administrators'..The platform administrators are also in charge of running the deployment tools and of importing the platform and channels configuration at deployment or update time.
-
end-users interact with the platform only through Kibana and its (optional) punchplatform plugin. End-users are at most allowed to edit only selected configuration items ; for example edit a kibana dashboard or a resource file used by pipelines or rules (through optional punchplatform kibana plugin resources editor function). They cannot however alter the pipelines architectures, define or change the settings of critical components such as Kafka or Elasticsearch resources.
Among other features, the punch deployer helps you create the working environment for the operators. The working environment of each operator consists in a unix account, on one or more servers, that will be equipped with the required and deployed binary packages and commands.
This is depicted next where the yellow server is the one where the operator environment will be deployed:
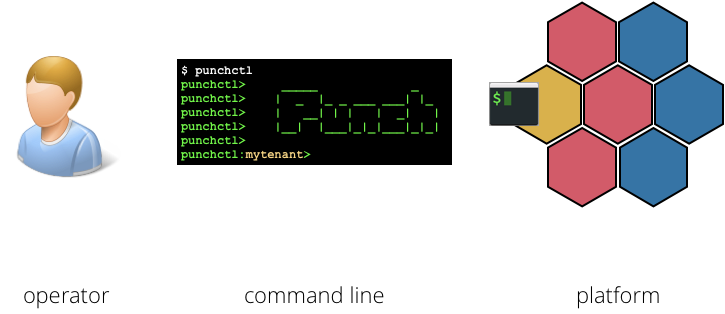
After that framework deployment step, and operator account initialization, there is no pipelines/application configuration deployed yet in the operator environment for the operator to start. I.e. no tenant nor channels nor applications/pipelines/rules. The platform is up, the framework ready and ready, but empty of applications and flows that make the specificities of the business-level solution.
The deployment operator must therefore create or import the first configuration, including global Elasticsearch indexation tuning, kibana dashboards, and per-tenants configuration folder of applications and pipelines (channels).
He has to import it so that it is available on all the operator servers, in each of the operator accounts environment, with some forethought to how these multiple operators will share and cooperate around these configuration copies. (Is it shared through a common folder, or is there some configuration management tool like git ?).
Once equipped with that configuration folder, each operator can start or update punch applications and pipelines.