Channels
Rationale¶
Using channels, you build a useful application from one or several pipeline(s) pipeline(s). Something useful requires in the general case a mix of different types of processings:
- ever-running streaming components : in charge of continuously collecting, transforming, indexing and storing your data.
- batch processing : to periodically fetch some data, compute some machine learning models, perform some batch aggregations to generate consolidated reports or KPIs, etc..
- administrative tasks : to take care of the data lifecycle, deleting expired data, moving data from hot to medium to cold storage, etc..
Our goal in designing the punch is to let you assemble all that with a minimal number of concepts. A channel is what groups all these functional items in a single consistent, monitored and managed entity.
A channel is defined using a single configuration file that has only two sections : applications and resources. Here is an example
{
version : "6.0"
applications: [
{
// supported types are storm|spark|shiva
type : storm
// the storm|spark|shiva cluster in charge of the job execution
cluster: main
// the name of the job. It refers to a job descriptor file
name: apache_parser
// the action to take when users request a 'reload' action
reload_action: kill_then_start
}
]
resources: [
{
type : kafka_topics
name : mytenant_apache_logs
cluster : main
partitions : 2
replication_factor : 1
}
]
}
Examples¶
Collecting logs¶
Here is a concrete simple example. Say you need a log management pipeline : receive logs, parse and transform them, and insert them into a database (elasticsearch).
Start simple : a channel can consists in a single process application to do just that as illustrated next:
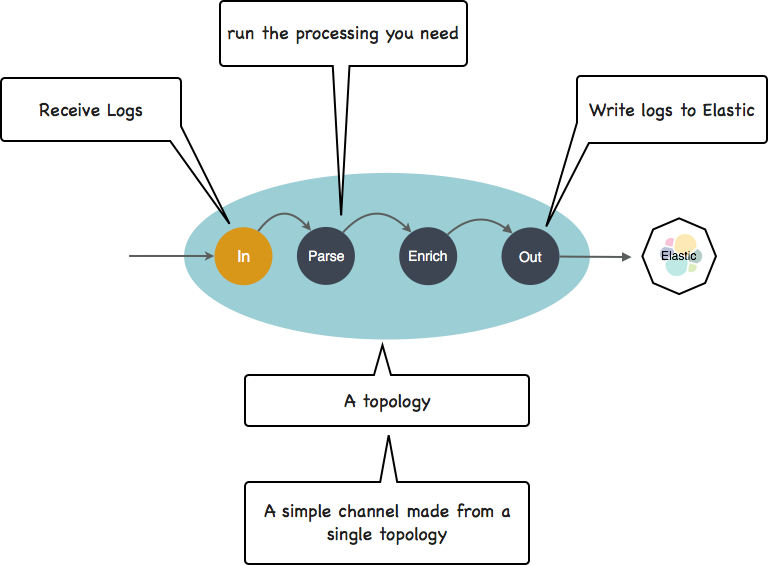
Note
we refer in there to a [punchline]. A punchline is simply a small directed graph of functions you assemble, most often using a simple input-filter-output pattern. Something made popular by logtash in the log management world. It turns out the punchplatform implements these graphs on top of a much more powerful technologies including storm topologies and spark topologies.
Now you go production. It is a good idea to add a queue to separate data ingestion from data processing and indexing. That is a recommended pattern that will allow you to deal with traffic peaks, and to restart your processing part with no impact on your ingestion part. It becomes this :
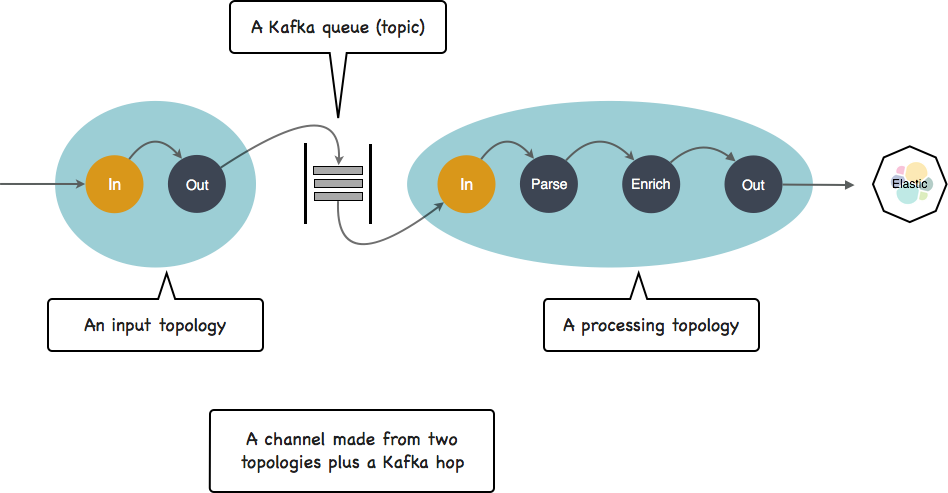
Your channel now consists in two applications plus another kind of resource a Kafka topic. Kafka is used by the punch whenever you need a queue, and just like any queueing technology it relies on topics to publish/subscribe to the data.
In both cases your channel is composed of stream processing component(s), plus a few associated resources (parsers, kafka topics). We represent such channels like this:
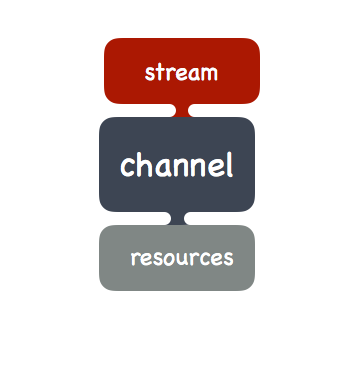
Machine Learning¶
Now say you want to improve your application with some anomaly detection cool feature. You will need to add some batch processing in there to compute some models, and tag your data using a mix of stream and batch logic.

You can do that easily by adding a machine learning application to your channel. It will then looks like this:
Periodic Data Fetching¶
Say now you need to execute every night some external fetching of third-party data. What you need is to define simple tasks by possibly integrating third-party applications. It could be an Elastic beat to go fetch some files for example.
Again that is extremely easy : just add it to your channel.
You can continue like this and add to a channel more processing and resources. This is very simple to do on the punch. You will end up with channels like this:
Summary¶
Most big data platforms rely on this concept of channel. Only the name differs (channel, pipeline, job, task etc..). Nifi, StreamSet, cdap are some well-known tools to design and run such pipelines.
The punch is similar, but provides the same clean and powerful concepts using a daringly simple, small-footprint and fully integrated platform.
Refer to the the channel chapter for details about configuring channels.