Architecture¶
Abstract
This chapter describes the punch overall architecture. The punch modularity makes it possible to deploy a small single-server solution up to a large scale platform. This modularity is sometimes confusing if you try to understand what the punch architecture is, and how it compares with other platform, stack or siem. Hopefully this chapter will explain it all clearly.
What you want to solve¶
The punch helps you to solve some (or all) of the following types of use cases.
The punch is not a monolithic platform. It is built on top of a number of software modules and components. Some are directly integrated from opensource projects (elasticsearch, kafka, spark etc.. ), others are proprietary and developed by the punch team (data parsers, machine learning modules, archivers etc..).
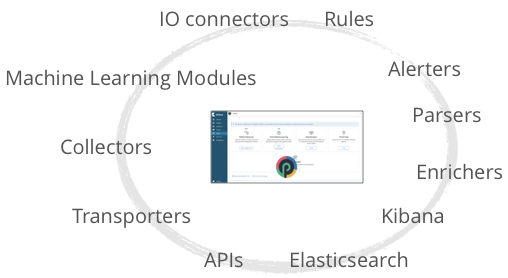
But that alone does not solve your problem. It can even be your nightmare should you need to work on your own to assemble these modules and components into a multi-tenant consistent application. What you need is a fully integrated solution, secured, packaged, monitored along with a simple declarative but powerful configuration management scheme.
In this chapter we focus on the punch architecture part. Before we describe a few typical setups you can achieve out of the box with the punch, here are the main characteristics of the punch architecture:
- no single-point-of failure: the punch requires no shared storage, no active-passive database. It installs itself on one or more than three servers.
- Multi-Tenant: everything is defined per tenant. You should not consider using a non multi-tenant platform or technology.
- Secured : security matters, of course, just like multi-tenancy.
- Scalable : you can (should) start small. You will be able to grow without pain.
Here is how it looks like depending on your hosting capabilities:
On Premise¶
Consider first that you have your own servers (vms or native os) network and storage equipments. Say you need a large scale scalable platform to deal with lots of traffic, to archive lots of data over long periods of time, and provide search and data visualisation. In short, you need something like a log management solution, a SIEM, a monitoring data lake etc..
Punch deployed to deal with such use cases look like the following.
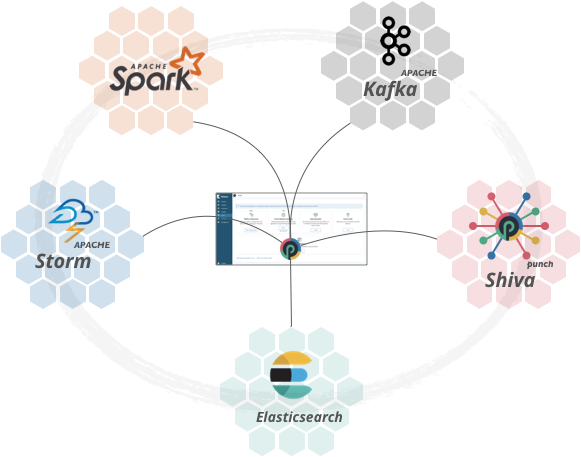
I.e. the punch deployer will install and configure what you need on your servers. All you have to do is to configure the functional pipelines to solve your business cases. Refer to the pipeline chapter to understand why we speak in terms of pipelines.
The central control center illustrated here is the punch operator console. It provides both cli admin commands, and a (Kibana plugin) web interface. This is the central location from where you operate your platform.
Information
One component in there is certainly not known to you : shiva. Shiva is a lightweight job scheduler used by the punch to run ever-running or periodic tasks such as spark apps, logstash instances or administrative tasks. See it as a lightweigh kubernetes. It has far fewer capabilities than kubernetes, and hence far simpler. It is production ready and can be used on tiny to large scale clusters.
On Clouds¶
Consider that you need the same application, but you run instead on a cloud environment. Most cloud providers offer the required components (elasticsearch, kafka, spark etc..) as managed services. They also offer additional options to deploy processing units such as serverless functions or managed kubernetes services.
The punch you will deploy is basically the same but will (may) take advantage of these managed services.
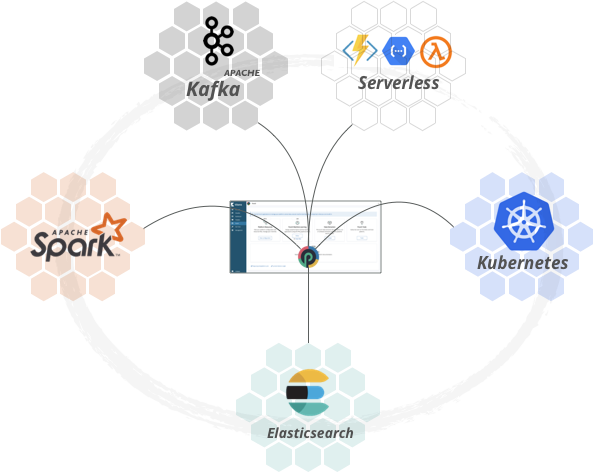
You may wonder : has the punch some value in that space ? Why not going completely cloud-native on your selected Google|Aws|Azure|Ovh|... provider ? Here are the reasons:
- cloud native also requires hard work, in particular the one the punch solves already in terms of configuration management and orchestration.
- do you really want to heavily depend on one provider ?
- Have you experienced managing hundreds of Tbs in a managed (or not) elasticsearch ? Checkout the excellent aws documentation to deal with large scale elasticsearch clusters on aws. Using the punch you benefit from years of running elasticsearch clusters, stream and batch applications. Being on cloud does not save you from the same tunings and operational difficulties. It simply saves you from struggling with the infrastructure and component deployments.
On the Edges¶
Consider last you need some punch features but on limited hardware resources: one, three or a few servers. The punch can run in a tiny system (a single process) or be partially of fully deployed on a few servers. Here is an example with only elasticsearch, and the shiva job scheduler. Such a platform can be used to provide machine learning streaming pipelines onto a small edge platform.
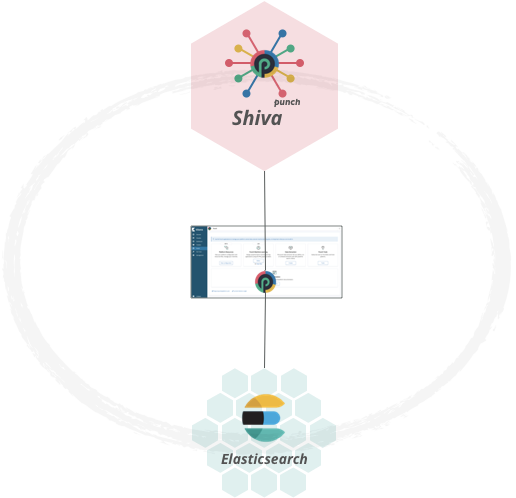
Conclusions¶
The punch integrates many modules and components already battle-tested in various production environments. Its architecture is simple, robust and scalable. It is meant to provide users with a highly integrated solution, with a strong focus on configuration management and ease of use.
It is already cloud compatible and will certainly quickly evolve in that space, as more and more project(s) will use ot on cloud native environments. It is and will always be an ideal fit for on-premise and edge use cases.
Here is a list of integrated Punch-specific and external Open-source components