Spark Punchlines¶
Although spark punchlines are expressed as storm punchlines, expected behaviour differs.
The basic difference is they can work in batch mode. A node is then executed only once during the punchline lifetime. Nodes are triggered lazily. In other words, data are made available only when an action is requested by a subscribed node, for instance an aggregation...
In streaming nodes, spark punchline behaves like storm ones.
Execution Mode¶
Spark natively offers the possibility to execute your punchline using various modes: client, cluster or local.
Have a look at the punchlinectl tools, these modes are documented inline. On a spark production cluster the client and cluster mode will have different behaviours. Below is a small summary of what can or cannot be done:
| Mode | File broadcasting? | Background? | File broadcasting with shiva? |
|---|---|---|---|
| foreground | True | False | True |
| client (local) | True | False | True |
| client (remote) | True | True | True |
| cluster | True | True | True |
Tip
In case your application needs external resources (eg. some_file.csv), it is recommended to have shiva deployed on each spark nodes for cluster mode execution.
Here is a graphical representation of these various mode.
Foreground¶
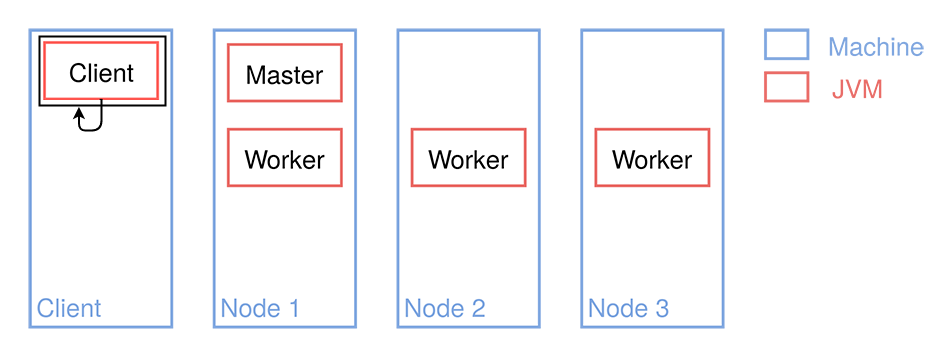
Client (local)¶
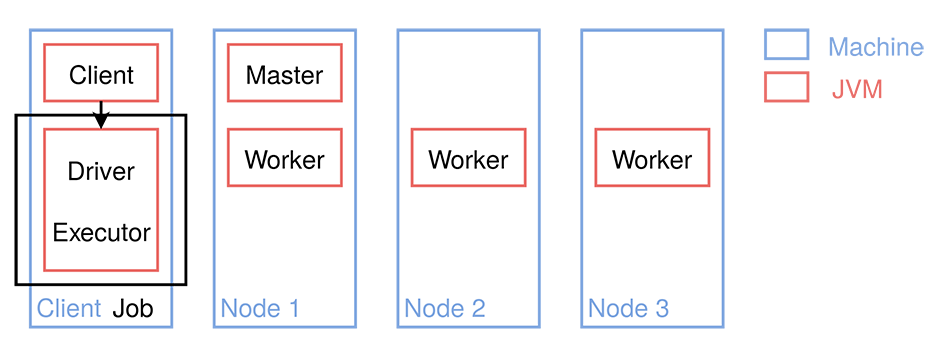
Client (remote)¶
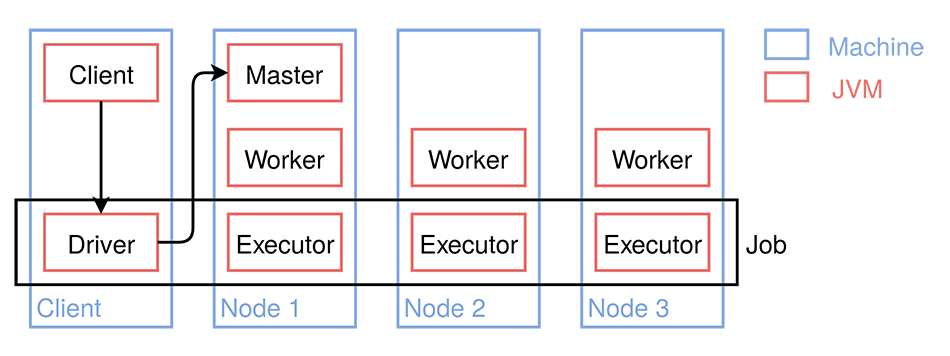
Cluster¶
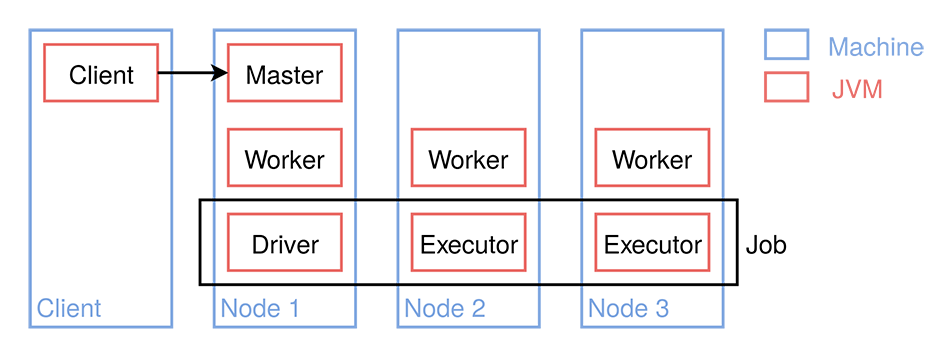
Spark Nodes¶
Let us start by describing how you define a node. We will describe next how you define the complete graph. Nodes are defined using the hjson format. Here is an example:
{
type: punchline
version: "6.0"
runtime: spark
tenant: default
dag:
[
{
type: dataset_generator
component: input
settings:
{
input_data:
[
{
age: 21
name: phil
musician: false
friends:
[
alice
]
}
{
age: 23
name: alice
musician: true
friends:
[
dimi
]
}
{
age: 53
name: dimi
musician: true
friends:
[
phil
alice
]
}
]
}
publish:
[
{
stream: data
}
]
}
{
type: show
component: show
settings:
{
truncate: false
}
subscribe:
[
{
component: input
stream: data
}
]
}
]
}
As you see, if you assemble several nodes, you have your complete Graph, that is, your punchline. A dag in array of nodes. The graph is implicitly defined by the subscribe-publish relationship.
Published Values¶
In each node, the publish array defines the value or list of values published by a node.
Each value is named, and can be disambiguated by an optional tag. Tags are explained below.
What you must first understand is what are the published values.
The rule is simple : most nodes publish a single Dataset
Here is an example. The following node reads a csv file and publishes its contents
as a dataset. Each line of the file will be converted to a row. Hence the published value
is of type Dataset<Row>.
{
type: punchline
version: "6.0"
runtime: spark
tenant: default
dag:
[
{
type: file_input
component: input
settings:
{
format: csv
path: ./AAPL.csv
}
publish:
[
{
stream: default
}
]
}
]
}
Subscribed Values¶
The subscribe field defines the list of value a node subscribes to.
This basically defines the node input parameters.
Here is an example you are likely to use a lot : the show node. The following is a complete
PML that will print out to stdout the Dataset generated by the file_input node:
{
type: punchline
version: "6.0"
runtime: spark
tenant: default
dag:
[
{
type: file_input
component: input
settings:
{
format: csv
path: ./AAPL.csv
}
publish:
[
{
stream: default
}
]
}
{
type: show
component: show
subscribe:
[
{
stream: default
component: input
}
]
publish:
[
{
stream: default
}
]
}
]
}
If you execute this punchline the following output is displayed:
punchlinectl --punchline csv_files_to_stdout.hjson
SHOW:
+----------+----------+----------+----------+----------+----------+--------+
| _c0| _c1| _c2| _c3| _c4| _c5| _c6|
+----------+----------+----------+----------+----------+----------+--------+
| Date| Open| High| Low| Close| Adj Close| Volume|
|2017-12-28|171.000000|171.850006|170.479996|171.080002|171.080002|16480200|
|2017-12-29|170.520004|170.589996|169.220001|169.229996|169.229996|25999900|
|2018-01-02|170.160004|172.300003|169.259995|172.259995|172.259995|25555900|
|2018-01-03|172.529999|174.550003|171.960007|172.229996|172.229996|29517900|
|2018-01-04|172.539993|173.470001|172.080002|173.029999|173.029999|22434600|
|2018-01-05|173.440002|175.369995|173.050003|175.000000|175.000000|23660000|
|2018-01-08|174.350006|175.610001|173.929993|174.350006|174.350006|20567800|
|2018-01-09|174.550003|175.059998|173.410004|174.330002|174.330002|21584000|
|2018-01-10|173.160004|174.300003|173.000000|174.289993|174.289993|23959900|
|2018-01-11|174.589996|175.490005|174.490005|175.279999|175.279999|18667700|
|2018-01-12|176.179993|177.360001|175.649994|177.089996|177.089996|25418100|
|2018-01-16|177.899994|179.389999|176.139999|176.190002|176.190002|29565900|
|2018-01-17|176.149994|179.250000|175.070007|179.100006|179.100006|34386800|
|2018-01-18|179.369995|180.100006|178.250000|179.259995|179.259995|31193400|
|2018-01-19|178.610001|179.580002|177.410004|178.460007|178.460007|32425100|
|2018-01-22|177.300003|177.779999|176.600006|177.000000|177.000000|27108600|
|2018-01-23|177.300003|179.440002|176.820007|177.039993|177.039993|32689100|
|2018-01-24|177.250000|177.300003|173.199997|174.220001|174.220001|51105100|
|2018-01-25|174.509995|174.949997|170.529999|171.110001|171.110001|41529000|
+----------+----------+----------+----------+----------+----------+--------+
only showing top 20 rows
root
|-- _c0: string (nullable = true)
|-- _c1: string (nullable = true)
|-- _c2: string (nullable = true)
|-- _c3: string (nullable = true)
|-- _c4: string (nullable = true)
|-- _c5: string (nullable = true)
|-- _c6: string (nullable = true)
If you are familiar with Spark or with any machine learning notebook, you will be at ease.
Arithmetic Operation¶
For any operation where an arithmetic operation should take place, refer to the sql node.
This node gives you the ability to use SQL Query on your Dataset.
Punchline Execution¶
Please refer to the Executing Punchlines section.