Syslog Output¶
The syslog bolt works the other way the Syslog spout works : it takes one or several destination address(es) and forwards the lines it receives from the Storm previous bolt(s) to one or several destination using a load-balancing algorithm.
The SyslogBolt supports SSL/TLS and compression. For efficiency the SyslogBolt relies on an internal queue, in order to perform bulk writes towards the server, as well as supporting a good level of compression. Check the real time reported metrics to estimate the compression level or your bolt.
Because the Syslog bolt does not rely on an acknowledged protocol, sent data can be lost in case the remote peer fails or restart. The SyslogBolt will acknowledge the Storm tuples without ensuring the corresponding data has been received and processed by the Server. The configuration parameters of each destination are the following:
host: String / target host ip or nameport: Integer / target host ip portcompression: Boolean : false / Zlib netty compressionconnect_timeout_ms: Integer : 3000 / socket connection timeout (ms)connect_retry_interval_ms: Integer : 3000 / periodic reconnection interval (ms)drop_if_queue_full: Boolean : false / drop data strategysend_queue_size: Integer: 1000 / send data queue size
As part of a destination you can also add a rate limiting strategy. The only supported strategy is the fixed rate strategy, i.e. defining a maximum throughput expressed in log per seconds. To activate rate limiting add the following two properties to the destination:
load_control/ load control strategy "none" or "rate"load_control.rate: Integer / rate limit in log per second int > 0
Info
in general rate limiting is set at the spout level. For example say you read from Kafka and forward to a third-party TCP applications not supporting more than 10Keps. If you set a rate limiter at the KafkaInput level, set at 10Keps. It will work in average. But from time to time, you will observe higher throughput to your third party apps. This is because sockets IOs are buffered and performed asynchronously in the PunchPlatform. To have finer control, you must set an additional rate limiter associated to your destination. Even so, this value may be exceeded because of the internal buffering of the TCP sockets and networks between the topology and the third party apps.
An additional parameter is defined at the level of the spout, and will apply to all destinations:
acked: Boolean : false / acknowledgement strategy
Here is a complete example configuration:
{
"type": "syslog_output",
"settings": {
"acked": false,
"destination": [
{
"proto": "tcp",
"compression": false,
"host": "localhost",
"port": 9999,
"drop_if_queue_full": false,
"queue_size": 1000,
"load_control": "none",
"load_control.rate": 10000,
"connect_retry_interval_ms": 3000,
"connect_timeout_ms": 3000
}
]
},
"executors": 1,
"component": "myTcpSpout",
"subscribe": [
{
"component": "previous_spout_or_bolt",
"stream": "logs",
"grouping": "localOrShuffle"
}
]
}
Using several destination addresses allows you to benefit from high-availability without requiring a virtual destination IP address on the server side.
SSL/TLS¶
To learn more about encryption possibilities, refer to this SSL/TLS configurations dedicated section.
Destination Groups¶
A single syslog bolt can be configured with several destination addresses. It will then load balance the data using a round robin strategy. Should one of the destination fail, the bolt will keep writing to others. Periodic reconnection attempts are regularly performed to eventually reconnect to all destinations.
You can further configure the destination addresses as part of groups. A group is a logical grouping of several destination typically part of the same cluster (or room, or site, etc..). A destination address associated to a group is given a weight. The weight of the group is the sum of the weight of each connected address. The bolt sends data only the to destinations addresses for the heaviest group. Let us see an example to make this clear:
{
"type" : "syslog_output",
"settings" : {
"destination" : [
{ "group" : "primary", "weight" : 100, "host" : "125.67.67.10", "port" : 9999 },
{ "group" : "primary", "weight" : 100, "host" : "125.67.67.11", "port" : 9999 },
{ "group" : "primary", "weight" : 100, "host" : "125.67.67.12", "port" : 9999 },
{ "group" : "secondary", "weight" : 60, "host" : "125.67.67.20", "port" : 9999 },
{ "group" : "secondary", "weight" : 60, "host" : "125.67.67.21", "port" : 9999 },
{ "group" : "secondary", "weight" : 60, "host" : "125.67.67.22", "port" : 9999 }
]
},
...
}
With such a settings, the bolt will be ready to send data to destinations of either the group. If all six corresponding servers are up and running, and the bolt successfully connects to all, the primary group will be chosen, having a total weight of 300. If one of the server is stopped, the primary group weight changes to 200. That is still greater than the weight of the secondary group (180). Hence the traffic keeps being sent to the remaining two destinations of the primary group.
If however a second destination of the primary group is stopped or crashes, the bolt will start sending the data to the secondary group destinations addresses.
Groups are a simple way to combine load-balancing to several destinations (part of the same group), and switchover to backup systems, switching from a preferred primary group to a backup secondary one.
Note
the rationale of using groups is to free you from setting up complex virtual IPs on the server side. Virtual IPs are not trivial to setup in a way to benefit from an active active load-balanced solution.
Streams And Fields¶
The SyslogBolt sends lines of data onto a Socket. It typically expects to receive from Storm a single field on its input stream/ In that case is simply forwards the value of that fields to the destination as illustrated next:
/ 
You should use the SyslogBolt that way, and configure it to receive from Storm a single-field stream. If however the SyslogBolt receives several fields, it will sends them as key value pairs delimited by '=' and a space. This is illustrated next.
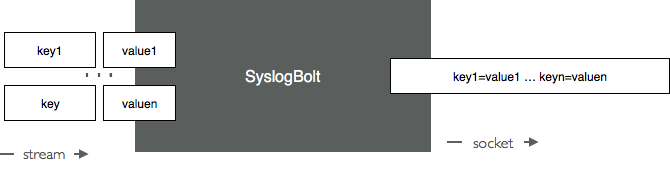
Warning
This makes little sense, a better option to forward pairs of key values is to select the Lumberjack format. Use instead the LumberjackBolt.
Acknowledgement Strategy¶
Please read this carefully.
If the syslog bolt is connected to none of its configured destination(s), you can make it block the processing of your topology, waiting for some destination to be available, or instead consider it harmless and drop these tuples.
You control that with the acked parameter, if set to true, Storm tuples will be acknowledged (in the Storm sense) only if it was successfully written to the output socket. More precisely :
- a tuple is acked if it was submitted for sending to a connected destination.
- a tuple is failed if no connected destination was available.
What happens if a tuple is failed ? it will be notified to the corresponding spout, the one that inserted the initial log into your topology. The KafkaInput, Syslog and File spouts will replay the failed logs. The SyslogBolt will keep receiving them, and eventually will find a working destination.
In contrast if you set the acked parameter to false, tuple will always be acked, even if no destination is connected. That protects your topology from being slow down because no remote server is available. Of course in that case, tuples will never be replayed.
Warning
Note that even if tuples are acked, it does not mean yet that the remote server has received the data. It only means the data is in the pipe towards that server. It you need real end-to-end acknowledgement with the remote server, use the lumberjack acknowledged protocol.
Another but related question is : what if the target server(s) are up and running but are too slow to keep up reading the SyslogBolt data ? The SyslogBolt can be configured to either slow down the topology rate, or to get rid of the slow server(s). You control that with the [drop_if_queue_full] parameter. If set to true, the SyslogBolt will end up disconnecting from slow servers. In that case, tuples will be failed or acked according to the [acked] parameter just described.
One of the two following settings are recommended:
- acked = true ; drop_if_queue_full = false : use this setting to limit loosing tuples. But know that if no servers are available, your topology will stop processing new data until servers come back.
- acked = false; drop_if_queue_full = true : tuples will always be acked, and your topology will never be slowed down by a slow server. Use this settings if your SyslogBolt must work in best effort : if destination servers are available, send the data, if not, drop the data.
Metrics¶
See metrics_syslog_bolt