PunchPlatform versus ELK¶
Abstract
The PunchPlatform can be used as an ELK (Elasticsearch-Logstah-Kibana) solution. It is a very common (and a very good) question to kown what exactly is the difference. This guide goes through a simple example to highlight the differences and similarities between the two platforms.
Logstash versus Topology versus Channel¶
Using logstash you usually do something like this :
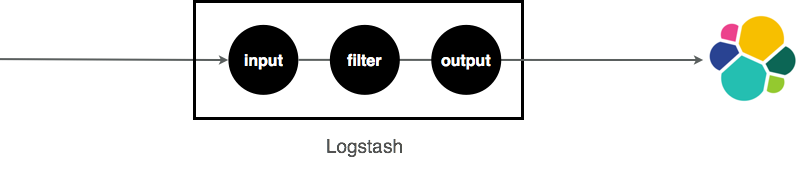
You start a logstash process, in charge of reading some data, transform
it and index it into Elasticsearch. Easy enough. The equivalent concept
used in the PunchPlatform is a punchline. It looks like this.
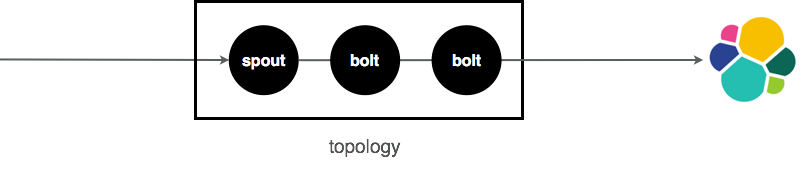
It is exactly the same idea but with a different processing engine. Instead of Logstash, you rely on a runtime inspired by the Apache Storm concepts. It is as easy but much more powerful as you are not limited to simple chain input-filter-output. You can setup arbitrary DAGs (directed-acyclic-graphs).
Note
The punchline DAGs were inspired (back in 2015) by apache Storm topologies. Storm concepts turned out to very simple yet sound and powerful, and brought us essential production-grade features such as end-to-end acknowledgements and scalability. Today punchlines run in various runtime environment, not necessary Storm. To make it clear Storm was our first runtime. SInce then punchline are capable of running in many others including Spark or plain java or python runtime. What remains from our first Storm adventure are the concepts of DAGs and nodes.
This said, coming back to this ELK comparison, a punchline can be as simple as a logstash.
It starts to be easier with the punch when you start creating a complete application,
i.e. something with more than a simple logstash. With the Punch you assemble several
punchlines into a channel. It starts looking like this.
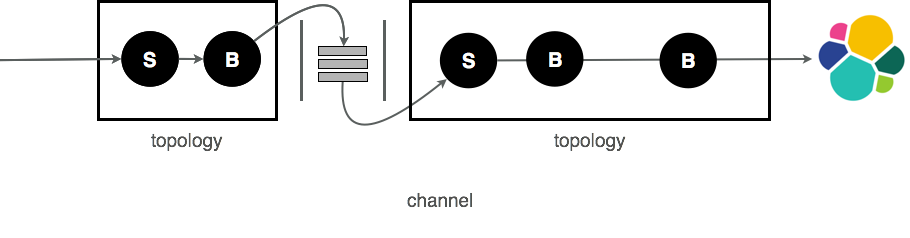
You can do that as well as using logstash. But don't ! You will spend a lot of time deploying, configuring and supervising many Logstash servers. That is already taken care of. You only need to write an extra JSON file to define your channel.
Important
When you prototype or discover Elasticsearch, do not hesitate to start with punchlines. These are easy to work with. You can then execute them using a simple command line terminal command, just like logstash. To submit them to a more elaborate runtime (Storm or Punch runtimes) you only have to make them defined as part of a channel. You will then benefit from all the Punch goodies in particular visualizing your punchlines metrics.
Yahoo Stock Example¶
We will use the example described in http://blog.webkid.io/visualize-datasets-with-elk. A simple dataset is taken from Yahoo's historical stock database. You can download the data as a simple CSV file. It looks like this:
2015-04-02,125.03,125.56,124.19,125.32,32120700,125.32
2015-04-01,124.82,125.12,123.10,124.25,40359200,124.25
2015-03-31,126.09,126.49,124.36,124.43,41852400,124.43
2015-03-30,124.05,126.40,124.00,126.37,46906700,126.37
2015-03-27,124.57,124.70,122.91,123.25,39395000,123.25
2015-03-26,122.76,124.88,122.60,124.24,47388100,124.24
The point is simply to ingest that data into Elasticsearch, then visualize it using Kibana.
The only significant difference between ELK and the PunchPlatform is about designing your input-processing-output channel. Using ELK you use a logstash configuration file, that combines it all in a single file.
Using the PunchPlatform you use a [punchline] configuration file and a [punchlet]. The punchline file defines the input-processing-output structure. It can be as simple as a straight sequence file-punchlet-Elasticsearch (as in this tutorial), to arbitrarily complex and distributed combinations.
As for the punchlet it contains the data transformation logic.
Tip
True, compared to logstash you have two files instead of one. The reason of
that is to clearly separate the processing logic (Parsing, enriching
normalizing the data) from the deployment and
configuration logic. It actually is a lot cleaner. You write your
punchlet once, and reuse it next in many different input/filter/output pipes.
Let us check the csv-processing.punch punchlet you need for this example :
{
csv("Date","Open","High","Low","Close","Volume","Adj Close")
.delim(",")
.inferTypes()
.on([logs][log])
.into([logs][log]);
}
Hopefully you guess what it does. It converts the CSV data into a clean JSON document ready to be inserted into Elasticsearch. What probably looks strange to you are the [logs][log] parts.
An example will best make that clear to you. The input data received by your punchlet looks like this:
{
"logs": {
"log": "2017-02-21,136.229996,136.75,135.979996,136.699997,24265100,136.699997"
}
}
After the punchlet it looks like this :
{
"logs": {
"log": {
"High": 137.119995,
"Low": 136.110001,
"Volume": 20745300,
"Adj Close": 137.110001,
"Close": 137.110001,
"Date": "2017-02-22",
"Open": 136.429993
}
}
}
The punchlet has simply replaced the input field [logs][log] by a new one consisting of key value pairs.
Compared to the Logstash filter syntax, the Punch Language is a real programming language, more compact and a lot more expressive than configuration files.
Next, you need to setup a topology configuration file to read this CSV file, run the punchlet and send the result to Elasticsearch. Let\'s take a look on what we get:
{
"name" : "file_injector",
"spouts" : [
{
"type" : "file_spout",
"settings" : {
"path" : "/tmp/csv-table-file.csv"
},
"storm_settings" : {
"component" : "file_spout",
"publish" : [
{ "stream" : "logs" , "fields" : ["log"] }
]
}
}
],
"bolts" : [
{
"type" : punchlet_node",
"settings" : {
"punchlet" : "examples/csv-processing.punch"
},
"storm_settings" : {
"component" : punchlet_node",
"publish" : [ { "stream" : "logs", "fields" : ["log"] } ],
"subscribe" : [
{
"component" : "file_spout",
"stream" : "logs",
"grouping": "localOrShuffle"
}
]
}
},
{
"type": "elasticsearch_bolt",
"settings": {
"cluster_id": "es_search",
"per_stream_settings" : [
{
"stream" : "logs",
"index" : { "type" : "daily" , "prefix" : "stock-" },
"document_json_field" : "log"
}
]
},
"storm_settings": {
"component": "elasticsearch_bolt",
"subscribe": [
{ "component": punchlet_node", "stream": "logs", "grouping" : "localOrShuffle" }
]
}
}
],
"storm_settings" : {
...
}
}
Note
Instead of using Logstash concepts (input, filters and output), you use Apache Storm concepts. Spouts are input functions, Bolts are both the processing and the output functions. Then, you describe your execution graph through this topology file.
To run this example, go to $PUNCHPLATFORM_CONF_DIR/samples folder.
You can run the topology using the following command.
cd $PUNCHPLATFORM_CONF_DIR/samples/punchlines/files/csv_to_stdout_and_elasticsearch
punchlinectl csv_to_stdout_and_elasticsearch.hjson
To go further, keep reading the original blog post and have fun visualizing your data !
Where to go from there¶
As you see, logstash and topologies are similar concepts. Both are pipelines. Where the punch clearly differentiates from ELK is to provide you with state-of-the-art pipeline technologies. Parsing logs is one thing, you are likely to need much more power : machine learning, aggregations, massive extractions, data replay, etc..
There is the difference.
Conclusion¶
We tried to make the Punch as simple as ELK to ingest data, try it out, prototype a solution. One of our customers designed its complete supervision solution in a just a week.
This said the learning curve to use the Punch is slightly steeper, because you have to be at ease with Storm concepts. But once comfortable, your way to production, performance and resiliency will be dramatically shorter.