File Output¶
Overview¶
The FileOutput writes incoming tuples into archives. Archives can be plain files on a posix like filesystem, or objects stored in an object storage solution such as a S3 or Ceph object store...
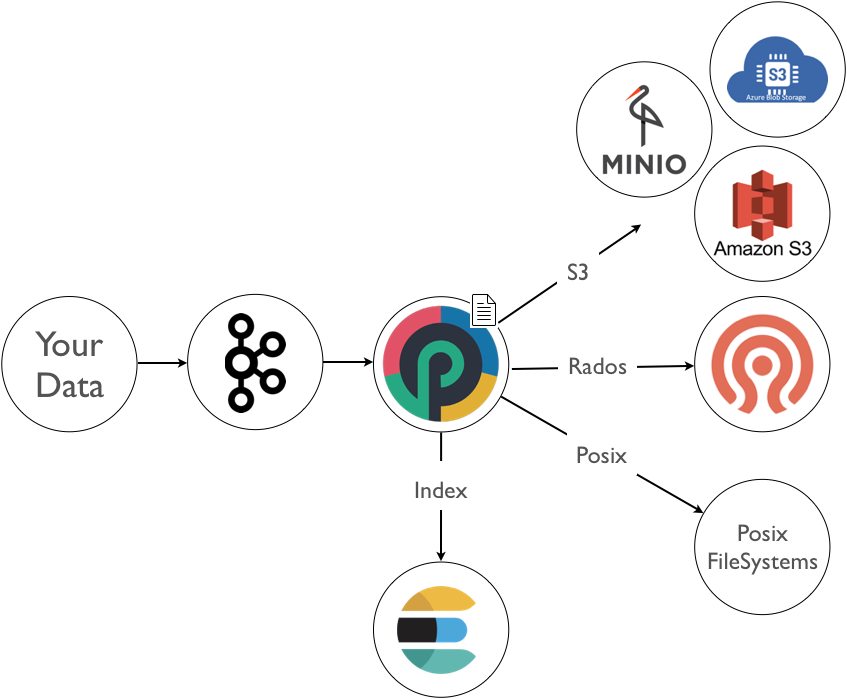
In all cases the FileOutput can generate additional metadata that can be stored in a separate store (typically Elasticsearch). This metadata provides you with additional capabilities to efficiently extract your data. Without it, you will be on your own to navigate through folders or object store pools to locate and extract the archives you are interested in.
Pay attention that if you deal with massive or long term archiving (months or years) you will end up with hundreds of millions of files. Executing something as simple as a file or object listing will take a considerable amount of time.
Activating metadata is thus strongly encouraged. It will also allow you to benefit from the punch housekeeping feature that periodically purge out of dated archives.
The FileOutput supports writing to a POSIX file system (typically a NFS to archive log on a third party storage solution), to a S3 or Ceph distributed object store. The punch deployer lets you deploy a Ceph cluster on your on premise infrastructure easily. S3 stores are typically provided by your Cloud provider. If you do not have one we strongly recommend the Minio open source S3 store.
Settings¶
Main Settings¶
| Name | Type | Default Value | Description |
|---|---|---|---|
| ** | |||
| destination** | String | - | Url of the destination device. Required if destinations not set. |
| ** | |||
| destinations** | String Array | - | Urls of the destination devices. Required if destination not set. |
| minio_cluster | String | - | |
| access_key | String | - | Access key for S3 Cluster |
| secret_key | String | - | Secret key for S3 Cluster |
| user | String | client | User for Ceph Cluster |
| strategy | String | at_least_once | Batching strategy. One of at_least_once, one_by_one. |
| streaming | Boolean | false | Filesystem only. If true, tuples are directly inserted into destination file, instead of a RAM buffer. |
| encoding | String | csv | Content encoding. One of csv, json, avro, parquet. |
| fields | String Array | - | Tuple's fields to be stored. If not set, all fields are selected. |
| timestamp_field | String | - | Field used to get timestamp of tuple (used for indexing). If not set, tuple processing time is used. |
| separator | String | __|__ | Csv fields separator. |
| pool | String | Tenant name | High-level isolated set of file. See Pools |
| topic | String | Channel name | Allows grouping files under a common label. See File Prefix |
| compression_format | String | NONE | Format used for compression. One of "NONE", "GZIP". |
| batch_size | Integer | 1 000 | Only for "at_least_once" strategy. Maximum number of tuples added to a batch. |
| batch_expiration_timeout | String | 10s | Only for "at_least_once" strategy. If no new tuples are added to a batch before timeout, batch is flushed. See Timeouts |
| batch_life_timeout | String | 0 | Only for "at_least_once" strategy. If batch reach before timeout, batch is flushed. See Timeouts |
| maximum_writes | Integer | Nb of destinations | Limit the amount of destinations a batch should be successfully written to. See Successful Writes. |
| minimum_writes | Integer | 1 | Set the amount of destinations a batch should be successfully written to. See Successful Writes. |
| file_prefix_pattern | String | %{topic}/%{partition}/%{date}/puncharchive-%{bolt_id}-%{partition}-%{offset}-%{tags} | Pattern used for object's prefix. See File Prefix. |
| batches_per_folder | Integer | 1 000 | Number of batch contained in a set. See File Prefix. |
| tags | String Array | - | Fields used to group tuples based on the corresponding value. See Batch Naming |
Advanced Settings¶
| Name | Type | Default Value | Description |
|---|---|---|---|
| create_root | Boolean | false | Create the root directory if it doesn't exists. |
| add_header | Boolean | false | Add header to beginning of csv file. Ignored if encoding is not csv or if fields are empty. |
| filename_field | String | - | Only for "one_by_one" strategy. Field to use to get filename. Overrides classic naming pattern. |
| bloom_filter_fields | String Array | - | Fields to use for bloom filter. Activate the use of bloom filter. |
| bloom_filter_expected_insertions | Integer | - | Required if using bloom filters. Should be batch_size * nb of bloom filter fields. |
| bloom_filter_false_positive_probability | Double | 0.01 | False positive probability used in bloom filter. |
| hadoop_settings | Map | - | Additional hadoop fs settings as Map. |
| charset | String | utf-8 | Charset to use when encoding bytes to string. |
Deprecated Settings¶
These settings are still available for compatibility but should not be used anymore.
| Name | New strategy |
|---|---|
| cluster | Replace with destination parameter |
| batch_mode | Replace with correct strategy : false -> one_by_one ; true -> at_least_once |
| folder_hierarchy_pattern | Replace with file_prefix_pattern |
| filename_prefix | Place prefix directly in file_prefix_pattern |
| batch_expiration_timeout_ms | Replace with batch_expiration_timeout |
Destination Devices¶
The FileOutput supports 3 types of devices : plain posix filesystem, Ceph cluster and S3 Minio Cluster. The FileOutput identifies the client to use depending on the prefix of the provided url.
You must provide at least one url. If only one url is provided, you can use the destination parameter. If you have to
provide multiple urls, you can use the destinations parameter.
If multiple destinations are configured, they should all have the same type.
Tip
No matter your device, all the other parameters still apply !
Filesystem¶
To use a Filesystem implementation, your url must match the pattern file://<path>.
ex : file:///tmp/storage
The path defines the root directory used for archiving. If this root-directory doesn't exist on the processing node, an exception is raised, and the writing fails.
Warning
For the sake of simplicity when testing, the option create_root can be activated. This option allows root directory
to be automatically created.
We do not recommend activating this option.
Setting this option to true may create unwanted directories if destinations are mistyped.
Furthermore, not creating root directory allows to check that destination cluster is reachable.
Ceph¶
To use a Ceph implementation, your url must match the pattern ceph_configuration://<configuration-file-path>.
ex : ceph_configuration:///etc/ceph/main-client.conf
The path provided must lead to the Ceph cluster configuration file, containing the required configuration to connect with Ceph cluster.
S3¶
To use a S3 implementation, your url must match the pattern http://<cluster-address> or https://<cluster-address>.
ex : http://192.168.0.5:9000/
It is also possible to use the minio_cluster field to get URL(s) from platform properties.
The url must point to a valid cluster address. A bucket with the tenant name should be created before starting the topology.
To authenticate to your cluster, your have to provide an access_key and secret_key.
Archiving Strategy¶
Batching Strategy¶
The FileOutput can be configured to group incoming tuples in different ways. We call that the "batching strategy", and
it is set in strategy parameter. These strategies are:
at_least_once: ensures that each tuple is processed at least once. Some duplicated tuples can be found in case of crash and restart of the punchline. This mode requires a KafkaSpout, sending additional_ppf_partition_idand_ppf_partition_offsetfields as part of the emitted tuple.one_by_one: write received tuples as files with no batching strategy. This very particular mode makes only sense to receive big chunks of data such as files or images, typically received on an HttpSpout.
Timeouts¶
A batch will only be flushed if one of these conditions is reached :
- Size limit
batch_sizehas been reached. - No tuple has been added to this batch for the duration set in
batch_expiration_timeout. - The batch has been alive for the duration set in
batch_life_timeout.
Both timeouts can be set using elasticsearch time unit notation. Available units are d for days, h for hours,
m for minutes and s for seconds (ex : "10s"). You can also set a number (as string) representing the millisecond but
keep in mind that the precision of these timeouts is limited to second.
For example, setting batch_expiration_timeout to 5m will ensure that a batch is flushed if no tuples has been added
in the last 5 minutes. Settings batch_life_timeout to 2h will ensure that a batch will be flushed at most 2 hours
after its creation.
You can disable these timeouts by setting a value of 0.
Successful Writes¶
To enforce tuple acknowledgement, you can set a range of required successful write.
Settings the minimum_writes parameter ensure that data will be successfully written to at least this amount of
destinations. If the number of successful writes goes below this parameter, a fatal exception is raised, and the
processing stops. By default, this parameter is set to 1, so that a single successful write ensure success.
Settings the maximum_writes parameter ensure that data will be successfully written to at most this amount of
destinations. If the number of successful writes goes above this parameter, the FileOutput will not try to write to the
remaining destinations. By default, this parameter is set to the number of provided destinations so that no destinations
is ignored.
! note
1 | |
Streaming mode¶
A streaming mode is available when using filesystem device.
By default, the FileOutput will store tuples in RAM when creating batches. When the batch size or timeout is reached, this Batch is written to a file. When using streaming mode, the file is created on batch creation and tuples are written directly into it. This way, RAM is not used.
The Maximum/Minimum writes system explained above changes slightly when using streaming mode. On file creation, the
logic is the same. We must at least be able to open minimum_writes destinations, and we stop when maximum_writes
is reached. During batch creation, if a writing fails, we're not able to choose another destination. Therefore, this
destination is considered a failure. When the remaining destinations number goes below minimum writes, a fatal
exception is raised, incomplete files are deleted (when possible), and the processing stops.
To summarize, the maximum_writes limit is only used on file creation, and the minimum_writes limit is checked
whenever a writing fails.
Avro/Parquet Encoding¶
The Filebolt supports 4 kinds of encoding : csv, json, avro and parquet. While csv and json are the standard encoding described in this document, avro/parquet encoding works in a slightly different way.
First, you must provide the schema as a setting :
schema:
type: record
namespace: org.thales.punch
name: example
fields:
- name: _ppf_id
type: string
- name: _ppf_timestamp
type: string
- name: log
type: string
More information on avro schema on the apache documentation..
Also, note that, in this node, avro only supports snappy compression and parquet only supports gzip compression.
Finally, Avro/Parquet encoding only works in streaming mode on a filesystem and batching mode on S3.
Batch Naming¶
On top of the destination device, the batch follows a specific naming pattern. This hierarchy has 3 levels : the pool, the prefix, and the unique ID.
Pools¶
A pool simply groups all your archive files into high-level isolated sets. Most often you have one pool per tenant. It
provides isolation between your data.
The implementation of this concept depends on the device used :
- Filesystem : top folder (after root).
- Ceph : pool used in the cluster.
- S3 : bucket used in the cluster.
Tip
By default the pool is the tenant, and the topic is the channel. Unless you have good reasons, we recommend you stick to that pattern.
File Prefix¶
The file prefix follows the pattern provided in the file_prefix_pattern parameter. This pattern allows inserting
different parameters inside your prefix :
%{topic}: Thetopicparameter. Usually the channel, it allows grouping data that make sense for you to manipulate at once. For example, you can have one topic per type of logs (apache_httpd,sourcefire, etc...), or instead one topic by usage (security,monitoring, etc...). You are free to choose.%{date:<pattern>}: The date of the first received tuple of this batch. The tuple timestamp is either the value of thetimestamp_field, if this parameter is provided, or the timestamp of the first tuple arrival, i.e. the batch creation. The date is formatted with the pattern provided, or if non is providedyyyy.MM.dd(ex :%{date}is replaced by2020.04.10,%{date:MM}is replaced by04, etc...).%{batches_set}: Index of the batch set. Batches can be organized by set of given size. To set the size, use thebatch_per_folderparameter. When a set reaches this size, this index is incremented.%{partition}: The Kafka partition id. This parameter is ignored when usingone_by_onestrategy.%{offset}: Depends on the chosen strategy.at_least_once: The kafka partition offset.one_by_one: The batch offset. Every time a batch is written, this offset is incremented.
%{tag:<field>}: Value for given field. This field must be a tag field.%{tags}: All tags values separated by a dash.%{bolt_id}: A unique identifier for the component used.
Ex : %{topic}/%{date}/test/%{partitionId}/%{batches_set} with topic httpd, partition id 1 and a set index at 4
will give something like httpd/2020.04.10/test/9/4.
Unique ID¶
In order to ensure uniqueness and avoid filename conflicts, the filename structure is composed of a customizable prefix
and an imposed unique ID. The pattern used is \.avro, .parquet, .csv or .json. For csv and json, if compression, .gz is added. If the provided prefix
is empty, only the uuid is used.
Archive indexing¶
To deal with long duration and high-traffic archiving, the punch provides a powerful indexed archiving that uses an Elasticsearch index to keep track of what is saved.
In turn this will let you extract information more efficiently than scanning a unix folder.
Bloom filtering¶
The FileOutput leverage the bloom filter concept. This will allow exploring archives in a more efficient way. To
activate bloom filtering, just set the bloom_filter_fields. To configure your bloom filter, simply set these
parameters with desired value :
bloom_filter_fields: Fields to use for bloom filter.bloom_filter_expected_insertions: Expected insertion into this bloom filter.bloom_filter_false_positive_probability: False positive probability.
Tip
Learn more about bloom filtering on the wikipedia page.
ElasticSearch indexing¶
The FileOutput provides an output stream publishing the metadata of every archived batch. This metadata only concerns batches that have been successfully written to their destinations. To be able to explore your archives, you need to store this metadata in an ElasticSearch Index.
Tip
Even if you plan on storing this metadata somewhere else, we strongly recommend indexing it into ElasticSearch too. It is most likely you'll have to use the tools provided by the punch to inspect your archives, and all these tools rely on the ElasticSearch indexing of your metadata.
To use this, simply add an ElasticSearchOutput after your FileOutput and set the index prefix (usually "
Warning
Your prefix needs to be of form *-archive-* to apply the ElasticSearch template provided with the standalone.
You can find this template in $PUNCHPLATFORM_CONF_DIR/resources/elasticsearch/templates/platform/mapping_archive.json.
In particular, this template is necessary to use punchplatform-archive-client.sh tool presented later.
Batch Metadata¶
The metadata carries all the information you should have about your archived batch :
@timestamp: The timestamp indicating the metadata creation.file.uncompressed_size: Size of content.file.size: Size of file.file.name: Object full name. (Combining prefix and ID)file.encoding: File encoding.file.compression.format: Compression format.file.compression.ratio: Compression ratio ( >1 ).debug.component_id: Node id.debug.offset: Batch Offset. (See offset description in prefix section)debug.input_partition: Kafka Partition.batch.tuple_count: Number of tuples in this batch.batch.latest_ts: Latest tuple timestamp. (See date description in prefix section)batch.earliest_ts: Earliest tuple timestamp. (See date description in prefix section)batch.initialization_ts: The timestamp roughly indicating the indexing time.batch.digest: SHA256 digest of file when using Cephfields.names: Names of archived fields.fields.separator: Fields separator in csv content.bloom_filter: Bloom filter hash value.archive.devices_addresses: Addresses of the successfully written devices.archive.pool: Archive pool. (See pools)platform.channel: Channel used to archive this batch.platform.tenant: Tenant used to archive this batch.tags: Tags used, and their value. The topic is included in the tags.
Example :
{
"@timestamp": "2020-04-14T09:06:50.775Z",
"file": {
"uncompressed_size": 184500,
"size": 13317,
"name": "httpd/2020.04.14/puncharchive-0-1003-httpd-h2GnX3IBWWcd3bmsvUmw.csv.gz",
"encoding": "CSV",
"compression": {
"format": "GZIP",
"ratio": 13.854471727866636
}
},
"debug": {
"component_id": "urzwd3EBNj3z-fMfK9vE",
"offset": 1003,
"input_partition": 0
},
"batch": {
"tuples_count": 133,
"latest_ts": "2020-04-14T11:06:35.93+02:00",
"earliest_ts": "2020-04-14T11:06:33.692+02:00",
"initialization_ts": 1586855193711,
"fields": {
"names": [
"_ppf_id",
"_ppf_timestamp",
"log"
],
"separator": "__|__"
},
"bloom_filter": ""
},
"archive": {
"devices_addresses": [
"file:///tmp/archive-logs/storage"
],
"pool": "mytenant"
},
"platform": {
"channel": "apache_httpd",
"tenant": "mytenant"
},
"tags": {
"topic": "httpd"
}
}
Examples¶
Here are some examples of configuration. We'll consider that the tenant is mytenant and the channel is apache_httpd.
At least once¶
Take a look at the following KafkaInput published fields. You can see two PunchPlatform reserved
fields: "_ppf_partition_id" and "_ppf_partition_offset". When using the at_least_once
strategy, compared to the exactly_once, the FileOutput deals with the batching logic itself and not using the
KafkaInput anymore. This is why we must explicitly declare these two extra fields.
Here is an example of this configuration:
dag:
- component: kafka_reader
type: kafka_input
settings:
topic: <your_input_topic_name>
start_offset_strategy: last_committed
brokers: local
publish:
- stream: logs
fields:
- log
- _ppf_id
- _ppf_timestamp
- _ppf_partition_id
- _ppf_partition_offset
- component: file_output
type: file_output
settings:
strategy: at_least_once
destination: file:///tmp/archive-logs/storage
compression_format: GZIP
timestamp_field: _ppf_timestamp
batch_size: 1000
batch_expiration_timeout: 10s
fields:
- _ppf_id
- _ppf_timestamp
- log
subscribe:
- component: kafka_reader
stream: logs
publish:
- stream: metadatas
fields:
- metadata
- component: elasticsearch_output
type: elasticsearch_output
settings:
cluster_name: es_search
index:
type: daily
prefix: mytenant-archive-
document_json_field: metadata
batch_size: 1
reindex_failed_documents: true
error_index:
type: daily
prefix: mytenant-archive-errors
subscribe:
- component: file_output
stream: metadatas
For the sake of the illustration this example added two useful behavior:
- compression is activated. You can use "GZIP" or "NONE" to disable compression.
- one of the tuple field is used as timestamp as indicated by the
timestamp_fieldproperty. This tells the FileOutput to use that incoming field as an indication of the record timestamp. This in turn is useful to generate, for each batch file, an earliest and latest timestamps, used for naming files or for indexing purpose. If you do not have such a ready-to-use field, the current time will be used instead.
If you run this topology, you will obtain the following archived files, with an ID that may be different:
/tmp/archive-logs/storage
└── mytenant
└── apache_httpd
└── 0
└── 2020.04.14
├── puncharchive-ooEjeHEBeuU3WQMkBTrm-0-1586858493604-apache_httpd-Yo-nX3IBWWcd3bmsgIz5.csv.gz
├── puncharchive-ooEjeHEBeuU3WQMkBTrm-0-1586858493605-apache_httpd-h2GnX3IBWWcd3bmsvUmw.csv.gz
...
You can control the folder layout using the file_prefix_pattern property.
Here is an extract of the first one:
31-05-2019 10:18:59 host 128.114.24.54 frank
31-05-2019 10:19:59 host 128.95.200.73 bob
31-05-2019 10:20:59 host 128.202.228.156 alice
Tip
Note that each line only contains the raw log value. This is what is configured in the FileOutput fields settings.
If you select more fields, fields are separated by a configurable separator.
One by one¶
In some situations, you may want to use the FileOutput to generate one file per incoming tuple, the one_by_one
strategy can be used for that special case. The example below illustrates this use case.
Note that the KafkaInput can be in "batch" mode or not, both case will work.
dag:
- component: kafka_reader
type: kafka_input
settings:
topic: "<your_input_topic_name>"
start_offset_strategy: last_committed
brokers: local
publish:
- stream: logs
fields:
- log
- _ppf_id
- _ppf_timestamp
- component: file_output
type: file_output
settings:
strategy: one_by_one
destination: file:///tmp/archive-logs/storage
timestamp_field: _ppf_timestamp
file_prefix_pattern: "%{topic}/%{partition}/%{date}"
fields:
- _ppf_id
- _ppf_timestamp
- log
subscribe:
- component: kafka_reader
stream: logs
In some situation, you may want to write incoming tuples to several files based on a Storm field value. On that case,
you can use the filename_field option. When enabled, for each tuple, the FileOutput gets this field value and uses it
as the filename. So in this situation, the previous input/nodes choose the final file name by setting the right value in
this field.
Device types¶
Changing the device type from FileSystem to Ceph or S3 only requires a little change in the destination and some credentials. Here are the different configurations :
- Filesystem :
settings: destination: file:///tmp/archive-logs/storage - Ceph :
settings: destination: ceph_configuration:///etc/ceph/main-client.conf user: client - S3 :
settings: destination: http://localhost:9000 access_key: admin secret_key: adminSecret
Scaling Up Considerations¶
Archiving topologies are designed to scale in a way to write batches of files in a safe and idempotent way. The question is : how do you scale to achieve enough parallelism to write lots of data coming from multi partitioned topics ?
In all case, a single FileOutput instance must be in charge of handling a single batch. The reason is simply that a batch is nothing more that a continuous sequence of record from the same Kafka partition. Having a complete batch handled by a single instance of the FileOutput guarantees that even after a failure/replay, the same batches will be regenerated with the same identifiers, and the same content.
You have four ways to enforce that one-batch-per-instance condition.
- Use a single FileOutput instance : this is of course the easiest solution to start with. That single instance will receive all the data from all the partition. The FileOutput is designed in a way to achieve parallel concurrent writing of several batches. This setup can thus be efficient enough for many use cases. Try it first.
- Use several instances of the FileOutput on top of a single kafka input. That works but use the grouping strategy to enforce that each node will receive all the records from the same Kafka partition.
- Use one FileOutput instance per partition. This is easy to configure, deploy as many instances of the KafkaInput as partitions, one dedicated for each partition, and set up a FileOutput for each of the input.
- if you ultimately need to deploy more nodes than you have partitions, use the grouping strategy.
Prefer the simplest solutions. A single process topology deployed on a multi-core server can achieve a high throughput.
Java documentation¶
To see the more in-depth configuration, refer to the FileOutput javadoc documentation .