File Input¶
The FileSpout reads the content of one or several files to inject them in the topology.
You can control the way the file input will delimit the input data. The simplest strategy is
to emit each line of the input file as one value. You can however deal with other patterns using the codec parameter explained
below.
By default, the file input launches a single dedicated thread per file to scan. If the file is closed/rotated/recreated, it will be continuously reopened and read.
You can set a directory path instead of a single file path, in which
case all the files in there will be continuously read. You can also
wait for a new file to be written in this directory, this one will be
automatically read. Last, you can set a pattern to match the name of
the files to scan, such as for example *.log. Note finally that just like
other nodes, you can include the rate limiter.
Here is a complete configuration example to read some files from a folder
{
"type" : "file_input",
"settings" : {
# the codec parameter tells the input how to truncate the
# file data ('line' is the default codec)
"codec" : "line",
# the path can be a file or a directory name
"path" : "/var/log",
# You can use regexes to select the files you want to read
# from the folder path
"path.regex" : ".*\\.log"
},
"storm_settings" : {
...
}
}
Info
the file input node will reemit any failed tuples (i.e. reemit the lines of files that have been signaled as failed by a downstream bolt). This makes the file input node robust and capable of coping with downstream failures. However, if the file input node itself is restarted, it will restart reading the files from the start or from the end. If you need more advanced and resilient data consuming, use the kafka input node instead.
File Reading Strategies¶
Watcher on a directory¶
You can activate the "watcher" feature on a specific path. This way, all files (in the initial path or any new subfolder) and archives (.zip,.gz) created in it will be read automatically.
To configure this watcher you can see the full description of parameters
watcher and watcher.process_existing_files. If you set the watcher.process_existing_files
option to true, any already existing file in the directory (and subdirectory) will be added
to the list of file to watch. Otherwise, they will never be treated, even if the
tail option is active.
Note, for every file you can chose to activate/deactivate the tail and
read_file_from_start options but do not deactivate both (or nothing will
never happened).
For example, the configuration above will act as a Bash command
tail -f /path/to/directory/*.log:
{
"type": "file_input",
"settings": {
"codec": "line",
"watcher": true,
"watcher.process_existing_files": true,
"tail": true,
"read_file_from_start": false,
"path": "/path/to/directory",
"path.regex": ".*\\.log"
},
..
}
Compressed Files and Archives¶
Different archives can be read by the file iput node : .tar, .tar.gz, zip
Files inside archives will be read, you don't need to extract files before launching FileSpout
Furthermore, compressed files can be also read with File input node
WARNING: Only on compressed files (.gz) are compliant, not groups of file nor filesystem trees.
For example, you can specify a zip file which containing other archives, files with different format and compressed files. Each file will be process by the File input node with the appropriate codec
Delimiting the Input Data¶
By default the File input node use the carriage return character to delimit lines.
The file spout supports multiline using a configuration similar to the syslog spout.
If you don't precise the codec parameter, file extension will be read to define the correct codec associated to the file type.
Files with .xml and .json extension will be read with xml and json_array codec respectively. Other files will be read with line codec.
In case you want to override this automatic codec definition, you can still use codec parameter
Watchout
If you specify a path with different files, codec parameter will override automatic codec definition for all files in folder.
The codec parameter can take the following values :
-
line:/ the file is read line per line. The carriage return character is expected.
-
json_array:/ With the json_array codec, the file will be streamed continuously in a way to delimit json array elements. / Each element is emitted as a separated tuple.
-
xml:/ With the xml codec, the file is streamed continuously in a way to delimit xml top level elements. / Each element is emitted as a separated tuple.
-
multiline:/ several lines will be grouped together by detecting according to a multiline pattern. / This is typically used to read in java stacktraces and have them emit in a single / tuple field. / / Use the 'multiline.regex' or 'multiline.startswith' to set the new line detection option.
Specific parameters for multiline codec :
-
multiline.regex/ String / / set the regex used to determine if a log line is an initial or subsequent line. You can also set a specific delimiter and a timeout
-
multiline.startswith/ String / / set the regex used to determine if a log line is an initial or subsequent line. You can also set a specific delimiter and a timeout
-
multiline.delimiter/ String : "\n"
/ / Once completed the aggregated log line is made up from the sequence of each line. / You can insert a line delimiter to make further parsing easier. -
multiline.timeout/ Long : 1000
/ / If a single log line is received, it will be forwarded downstream after this timeout, / expressed in milliseconds.
The xml and json codecs are very useful but only work on specific input data.
Consider the following examples using the json_array codec. Let's say your file contains a
single (possibly very big) json array:
[1, 2, 3]
Each element will be emitted, in this case, 1, 2 and 3..
Now, say that you have another structure with an enclosing object:
{"records":[ 1, 2, 3]}{"records":[4, 5, 6]}}
The json_array codec will again emit only the inner elements (1, 2, 3, 4, 5, 6).
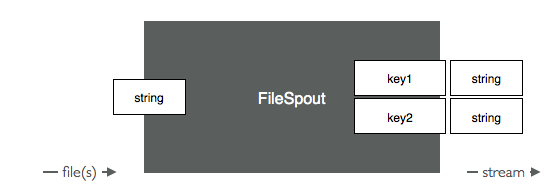
Streams And Fields¶
The file spout emits 2-fields tuple in the topology. One field is the read line, the other is the path of the file. The former can be named arbitrarily, the latter must be named . The logic of the file spout is illustrated next.
/ 
Here is a configuration example that emits line in the stream, using the fields .
{
"type": "file_input",
"settings": {
...
},
"storm_settings": {
"component": "my_file input node",
"publish": [
{
"stream": "logs",
"fields": [
"log",
"path",
"last_modified"
]
}
]
}
}
The File input node output its data to 3 special Storm fields. If you use these fields, they will a special value:
log: the data read from the filepath: the absolute path name of the originating filelast_modified: a timestamp of the file creation or last update time.
Parameters¶
To get a complete list of available parameter, see the FileSpout java documentation.
Metrics¶
See the FileSpout metrics section.