Punchlines¶
Abstract
The punchline is the base execution unit. It can represent arbitrary data processing pipelines, stream or batch. Punchlines are powerful and elegant but can lead to some confusion given the many possibilities. This essential chapter clearly explains the key punchline concepts.
Concept¶
To go straight, the Punch helps you to invent useful processing pipelines.
You do that using only a configuration file called a punchline.
Here is a typical example:
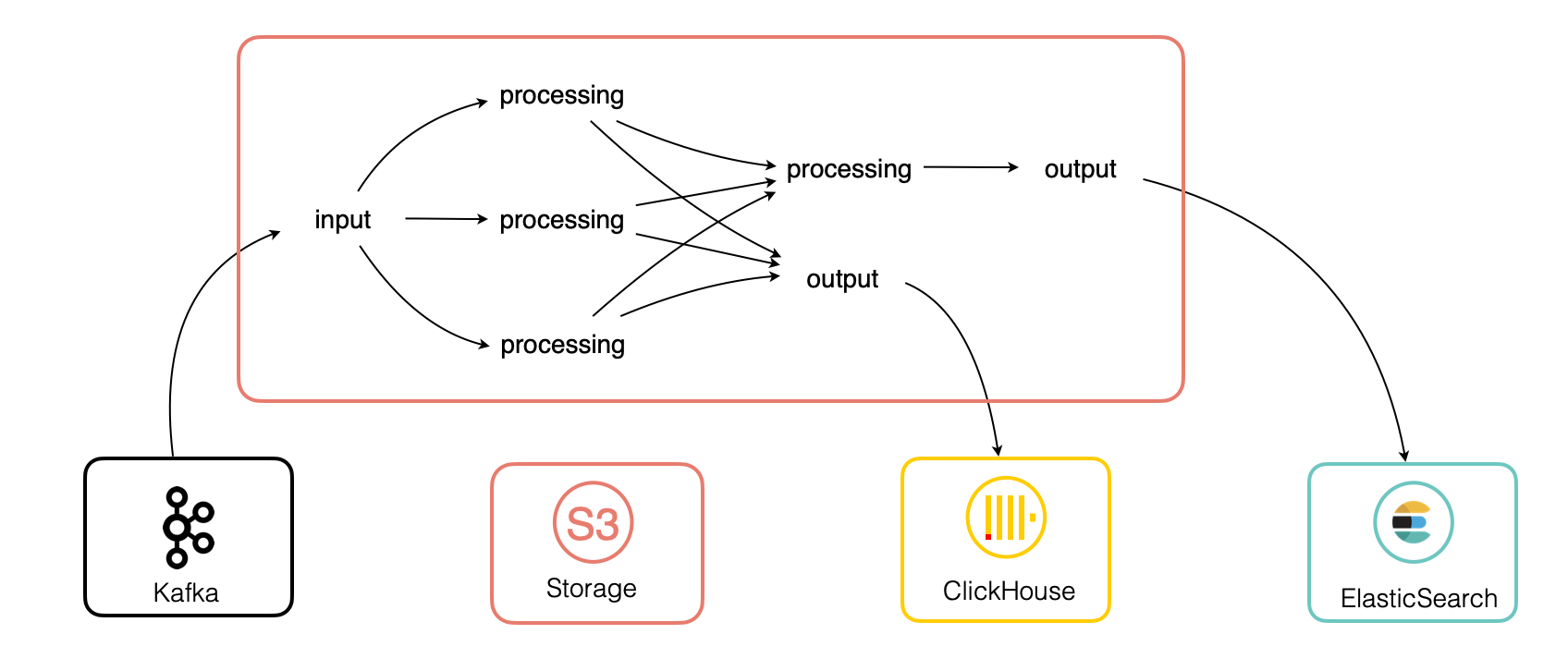
Configuration¶
Before describing the punchline file, note first that a punchline is always executed in the scope of a parent tenant and channel. The punchline also has a name, which by default is the radical of the punchline file.
These three identifiers (tenant, channel, application) are automatically used when starting a punchlines.
A punch application is represented as a direct-acyclic-graph (DAG) of steps called nodes. Each node can publish some values and subscribe to other node(s) published values. Think of a node as a function with in and out parameters. All that is expressed in a configuration file. A node can publish any type of data : tuples, numbers, datasets, machine-learning model, ...
You basically deal with three kinds of nodes:
- Input node in charge of fetching or receiving some data from some sources
- Processing nodes where you apply some processing logic to your data
- Output nodes to save your processing results to some data sink.
The overall structure of every punchline is identical. Here it is:
# Mandatory. The version is used for backward compatibility conversion
# and to ensure your punchline is conform to your platform.
version: "6.0"
# Mandatory. This is necessary to identify a yaml file as a punchline.
type: punchline
runtime: spark
dag:
-node
-node
settings:
resources:
- resource
- resource
Runtime¶
The punchline format is generic. Stream or batch, flink spark or pyspark, etc..
This said punchlines are only compatible to a
given runtime environment. A runtime environment here does not mean the actual runtime engine used
to run a punchline, but instead the class or type of runtime. Low latency record based processing or
micro-batching or batch processing ? Data-parallel centric or Task-parallel centric ?
These are key and crucial characteristics but highly technical and not easy to understand. The punch makes it easier to choose and provides you with fewer variants. Here they are:
storm: record based processing. This simple node only supports streaming punchlines:- java based
- task-parallel centric
- providing end-to-end acknowledgements and at-least-once semantics
spark: spark compatible runtime- java based
- data-parallel centric
- can deal with plain java spark or spark structured streaming capabilities.
- support dataframe spark api
- SQL support
pyspark: spark python variant. Same capabilities than spark but supports python nodes possibly mixed with java nodespython: plain python applications.- used for non-spark application. These can leverage your python libraries of choice: pandas, numpys etc..
Each runtime comes with specific settings and characteristics. As a rule of thumb :
- The
stormruntime is used for real time stateless processing such as ETLs, log shipping and parsing, routing data. It is based on a proprietary implementation runtime engine that conforms to the apache Storm API. - The
sparkandpysparkengines are used for stateful and batch applications such as machine learning applications, or to compute aggregations. They can also be used for stream use case, in particular to benefit from spark SQL and machine learning streaming capabilities. - The
pythonapplications are used for machine learning or any simple application that does not require to scale. If your data is small enough, python applications can do the job perfectly without the penalty to go through a distributed engine such as spark.
Important
The storm runtime environment does not imply that a storm cluster is actually required. These punchlines
run in proprietary lightweight engine that supports only stateless single-process graphs of nodes.
Similarly the punch provides single-process variants for spark, flink and pyspark engines,
best suited for small apps.
Settings.Resources¶
Understanding Resources and Packages¶
The resources parameter is one of the most important one. An example explains it clearly:
settings:
resources:
- punch-parsers:org.thales.punch:punch-core-parsers:1.0.0
- file:org.thales.punch:single-punchlet:1.0.0
- file:org.thales.punch:json-file:1.0.0
- punch-spark-pex:org.thales.punch.spark:alerting:1.0.0
- punch-spark-jar:org.thales.punch.spark:detection:1.0.0
- punch-storm-jar:org.thales.punch.stream:filter:1.0.0
What this allows you to do is to refer from packages installed on the platform.
Each package is described with
a classifier, a group identifier, an artefact identifier and a version number.
The classifier indicates the type of package.
- file means a plain file. You can use it to package any kind of file. An example would be to deploy a single punchlet, an enrichment files (possibly big hence compressed), images of whatever you need.
punch-parserrefers to a punch package that containsparsers. Parsers are archives containing one or several punchlets, grok pattern, resource files, unit tests etc..punch-spark-pexrefers to a pex python file that provides a pyspark compatible function.punch-spark-jarrefers to a jar file that provides a spark compatible function.punch-storm-jarrefers to a jar file that provides a storm compatible function.
Tip
This format is compatible with the maven usage. In fact the punch is compatible with mvn, and provides you with a robust, simple and safe procedure to deploy your custom modules, your parsers and your resources files. This can easily be combined with you CI/CD as well.
The punch-parserand file classifiers provides your punchline with the corresponding files that you can
then refer to inside your punchline.
Example¶
As an example here is a punch node that chain three punchlets
provided by the org.thales.punch:punch-core-parsers:1.0.0 package.
It also uses a resource file provided by a file artefact com.yourcompany.resources:http-codes:1.0.0 package.
- type: punchlet_node
settings:
punchlet_json_resources:
- com/yourcompany/resource/http-codes.json
punchlet:
- org/thales/punch/parsers/apache_httpd/syslog_header_parser.punch
- org/thales/punch/parsers/apache_httpd/parser.punch
- org/thales/punch/parsers/common/geoip.punch
The format to reference a resource in a node is artefactId/file path.
Warning
Reference to packages resources do not include the artefactId nor the versionId. The artefactId only identifies the container package name.
This works with the following resources:
settings:
resources:
- punch-parsers:org.thales.punch:punch-core-parsers:1.0.0
- file:com.yourcompany.resources:http-codes:1.0.0
asumming that punch-parsers:org.thales.punch:punch-core-parsers:1.0.0 reference a punch-core-parsers-1.0.0.zip file that contains:
org/thales/punch/parsers/apache_httpd/syslog_header_parser.punch
org/thales/punch/parsers/apache_httpd/parser.punch
org/thales/punch/parsers/common/geoip.punch
And assuming that file:com.yourcompany.resources:http-codes:1.0.0 reference a plain file
http-codes.json
Dag¶
The dag array provides the list of nodes. Each node has the following format:
type: punchlet_node
component: punchlet_node
publish:
- stream: logs
fields:
- field1
- field2
subscribe:
- component: previousNode
stream: logs
fields:
- field1
- field2
settings:
timeout: 20
I.e. a node subscribes to some data (from previous nodes) and publishes some data (to subsequent nodes). Input nodes only publish data, while output node only subscribe to some data.
The data flows between nodes are identified by a stream identifier. Here for example the stream of data
is called "logs".
Depending on the runtime environment (punch versus spark|pyspark versus python) the data traversing these streams can be of different nature: records, dataframe, vectors etc.. Refer to the documentation of each type for configuration details.
type¶
The type of the node refers to one of the punch provided node. Or to your own if you provide it to the punch.
component¶
That property uniquely identifies your node in the dag. Often you have a single node of each type. In that case you may omit the component property. It will be implicitly set to your node type.
When a node subscribes to another one, it refers that component identifier.
settings¶
Each node has its proprietary settings. These are grouped in the settings dictionary.
publish¶
Nodes can publish data to downstream nodes. Data is published onto so-called streams. A node can publish more than one stream. A typical example is to publish errors, regular data or alerts.
subscribe¶
Inner nodes subscribe to data from previous nodes. Each subscription includes the previous node component identifier.
Punchline Golbal Settings¶
In production, you may need additional settings, not at node level but for the whole punchline.
These settings (memory, concurrency...) depend on the runtime environement, so please refer to the