Log Central : Processor Punchlines (3)¶
Note
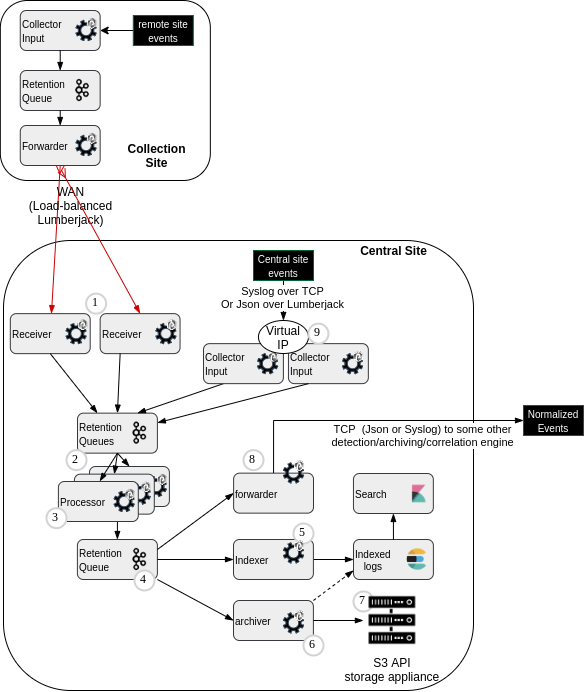
Click on this link to go to Central Log Management reference architecture overview
Key design highlights¶
Scalability¶
Scalability relies on multiple executors of the Punchlet node inside the punchline (executors setting).
It is possible to scale on more than 1 JVM or more than 1 server.
This is made possible by spawning other instances of the same application.
The Kafka input topic must have enough partitions so that each JVM consumes at least 1 partition.
Modularity through multiple processing punchlets¶
For reuse of punchlets, and to cope with the cases where a same data type is wrapped in different protocol envelopes (e.g. syslog-wrapped vs raw event), it is a good habbit to have successive punchlets, each dealing with one protocol layer, or increasing detail of processing.
E.g. processing an "apache daemon event" that reports inside a local log file, that is collected and forwarded by a rsyslog daemon, then sent to the punch 'syslog input node', then we would have need for the following succesive punchlets :
-
input.punch: responsible for retrieving metadata from the events records (i.e. information captured by the Punch input node, such as the_ppf_remote_host,_ppf_remote_port,_ppf_timestamp,_ppf_id... See reserved fields. The data remaining to be parsed is the syslog frame. -
parsing_syslog_header.punch: responsible for parsing just the syslog frame (event source device hostname, associated timestamp...). The data remaining to be parsed is the raw log line from the original log file. -
apache_httpd/parsing.punch: responsible for parsing the apache raw event, retrieving individual fields from the log line. -
...other punchlets for additional enrichment / normalization depending on the target data model (ECS, XDAS...)
Errors management¶
Because there is a punchlet_node in the punchline (for the parsing/normalization/enrichment), there is a risk of exception/error in the punchlet code.
This means that some specific processing output queue (in our example, the reftenant-errors topic) has to be identified to retrieve these unexpected documents, so as to not lose them (so that someone can later identify the problem, and requires changes in source device configuration, or device type discovery mechanisms).
This is very important, as even some unexpected slight change in input log format may cause a malfunction of a parsing expression developed on the standard format hypothesis.
Performance / CPU consumption / Scalability¶
Processing performance is limited by the throughput of the least efficient processing punchlets.
If too many processor/threads (executors) have to be allocated on a punchlet_node,
this may imply that one of the punchlet is not optimized and has to be refactored and unit-tested for CPU/processing-time efficiency.
Scalability can be achieved at small scale (up to several thousands EPS) by increasing the executors count of the punchlet_node.
The punchline internal mechanisms will load-balance the processing of tuples between these multiple instances,
up to the maximum number of threads allowed by the JVM.
If more threads/CPUs than a single JVM can have (because of VMs/servers sizing) are required, then the scalability must go one step further : having multiple instances of the same punchline.
To have more than 1 instance of a processing punchline means that the multiple instances will consume the same Kafka input queue. These instances must work concurrently and share the input flows. This is done by assigning a partition of the kafka input queue to each one. At least as many partitions as processing instances must exist in the source kafka topic.
Note
Increasing the partition number can be done without data loss in the kafka topic. However, it may require a restart of the producer punchline that writes data in the kafka topic. Kafka will rebalance produced data on the additional partitions. Please refer to HOWTO alter existing kafka topics.
Apache processor Punchline example¶
version: "6.0"
tenant: reftenant
channel: processor
runtime: shiva
type: punchline
name: apache
dag:
# Kafka input
- type: kafka_input
component: kafka_front_input
settings:
topic: reftenant-receiver-apache
start_offset_strategy: last_committed
encoding: lumberjack
publish:
- stream: logs
fields:
- log
- raw_log
- device_type
- subsystem
- es_index
- _ppf_timestamp
- _ppf_id
- stream: _ppf_metrics
fields:
- _ppf_latency
# Punchlet node
- type: punchlet_node
settings:
punchlet_json_resources:
- punch-webserver-parsers-1.0.0/com/thalesgroup/punchplatform/webserver/apache_httpd/resources/http_codes.json
- punch-webserver-parsers-1.0.0/com/thalesgroup/punchplatform/webserver/apache_httpd/resources/taxonomy.json
punchlet:
- punch-common-punchlets-1.0.0/com/thalesgroup/punchplatform/common/input.punch
- punch-common-punchlets-1.0.0/com/thalesgroup/punchplatform/common/parsing_syslog_header.punch
- punch-webserver-parsers-1.0.0/com/thalesgroup/punchplatform/webserver/apache_httpd/parser_apache_httpd.punch
- punch-webserver-parsers-1.0.0/com/thalesgroup/punchplatform/webserver/apache_httpd/enrichment.punch
- punch-webserver-parsers-1.0.0/com/thalesgroup/punchplatform/webserver/apache_httpd/normalization.punch
subscribe:
- stream: logs
component: kafka_front_input
- stream: _ppf_metrics
component: kafka_front_input
publish:
- stream: logs
fields:
- log
- raw_log
- device_type
- subsystem
- es_index
- _ppf_timestamp
- _ppf_id
- stream: _ppf_metrics
fields:
- _ppf_latency
- stream: _ppf_errors
fields:
- _ppf_timestamp
- _ppf_id
- _ppf_platform
- _ppf_tenant
- _ppf_channel
- _ppf_topology
- _ppf_component
- _ppf_error_message
- _ppf_error_document
- subsystem
- device_type
- raw_log
# Kafka output
- type: kafka_output
component: kafka_back_output_logs
settings:
topic: processor-logs-output
encoding: lumberjack
producer.acks: "1"
subscribe:
- stream: logs
component: punchlet_node
- stream: _ppf_metrics
component: punchlet_node
- type: kafka_output
component: kafka_back_output_errors
settings:
topic: processor-errors-output
encoding: lumberjack
producer.acks: "1"
subscribe:
- stream: _ppf_errors
component: punchlet_node
metrics:
reporters:
- type: kafka
reporting_interval: 60
settings:
topology.max.spout.pending: 2000
topology.component.resources.onheap.memory.mb: 120
topology.enable.message.timeouts: true
topology.message.timeout.secs: 30