Aggregations¶
Abstract
Performing continuous aggregations is a common and key function to compute consolidated indicators and metrics. It makes it possible to reduce the data cardinality and to continuously feed elasticsearch indices with ready-to-be-visualised data that would otherwise require complex and resource intensive queries.
Overview¶
The Punchline and plan features are a great fit to design and deploy such aggregation jobs on top of your elasticsearch (or any other data store) data. Here is what a complete production system looks like.
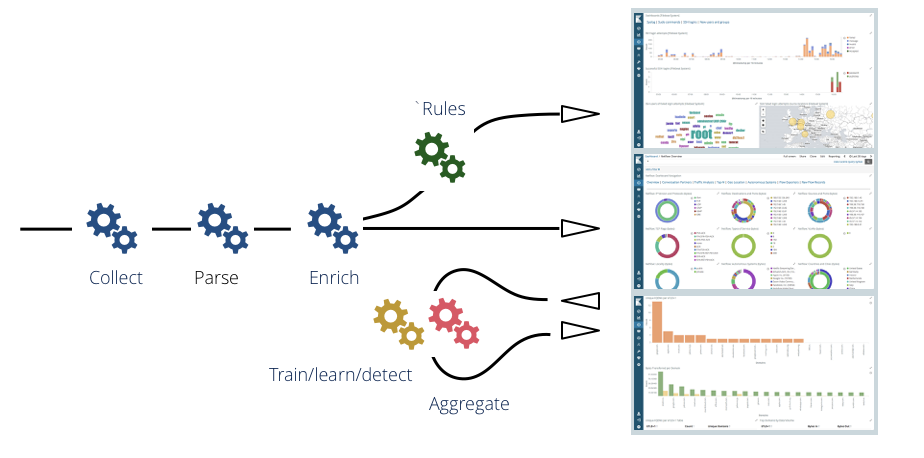
You typically have the stream pipelines in charge of ingesting your data and (in case you need it) preforming real time alerting. On the other hand you also have batch pipeline here illustrated in yellow and red to perform the many useful batch processing from computing ML models to this chapter's topic of aggregating data.
Here is a more focused illustration of the aggregation pipeline:

There are two possible strategies to aggregate elasticsearch data:
- By periodically fetching a complete (filtered or not) range of primary data. We will refer to this strategy as a batch strategy. You basically fetch a large number of elasticsearch documents, then aggregate them into your pipeline and write back the result to elasticsearch.
- By periodically performing aggregation elasticsearch requests instead of plain requests. The results of each aggregation request is actually a single document containing possibly many aggregation buckets. These buckets are in turn processed and consolidated into the aggregated index.
Let us see examples of both variants in action.
Tip
These example work on data produced by the punch standalone example pipelines. Do not hesitate executing them on your own.
Batch Strategy¶
Here is a complete example. The steps are:
- an
elastic_inputnode reads a timeslice of data from themytenant-events*index. - an aggregation is performed using the spark sql node.
- the resulting data is written back to elasticsearch, into the
apache_aggregation_metricsindex.
Note
this aggregation, and in fact most aggregation, do not require any coding. It only relies on the spark sql power.
{
type: punchline
version: "6.0"
runtime: spark
tenant: default
dag: [
{
type: elastic_input
component: input
settings: {
index: mytenant-events*
nodes: [
localhost
]
output_columns: [
{
type: string
field: target.uri.urn
alias: target_uri_urn
}
{
type: string
field: vendor
}
{
type: string
field: web.header.referer
alias: web_header_referer
}
]
query: {
size: 0
query: {
bool: {
must: [
{
range: {
@timestamp : {
gte : now-1180m
lt : now
}
}
}
]
}
}
}
}
publish: [
{
stream: data
}
]
}
{
type: sql
component: sql
settings: {
statement: (SELECT COUNT(*) AS TOP_5_uri, a.target_uri_urn, current_timestamp() AS timestamp, a.vendor, a.web_header_referer FROM input_data AS a GROUP BY a.target_uri_urn, a.vendor, a.web_header_referer ORDER BY TOP_5_uri DESC LIMIT 5)
}
subscribe: [
{
component: input
stream: data
}
]
publish: [
{
stream: data
}
]
}
{
type: elastic_output
component: output
settings: {
index: {
type: constant
value: apache_aggregation_metrics
}
http_hosts: [
{
host: localhost
port: 9200
}
]
}
subscribe: [
{
component: sql
stream: data
}
]
}
]
}
Elasticsearch Input Node¶
Here is now how you can leverage aggregation elasticsearch queries in the first place.
- an
elastic_inputnode performs an aggregation request. - the resulting document is an array, it is processed using a punch snippet of code.
- the aggregation is performed using the spark sql node.
- the resulting data is written back to elasticsearch, into the
apache_aggregation_metricsindex.
This strategy is the one often used as it benefits from elasticsearch power to perform the first level of aggregation using all its node, caches and indexing. Hence, only a limited dataset is returned to the spark pml job (in fact only buckets).
{
type: punchline
version: "6.0"
runtime: spark
tenant: default
dag: [
{
type: elastic_input
component: input
settings: {
index: mytenant-events*
nodes: [
localhost
]
query: {
size: 0
query: {
bool: {
must: [
{
range: {
@timestamp : {
gte : now-10000m
lt : now
}
}
}
]
}
}
aggregations: {
by_channel: {
terms: {
field: vendor
}
aggregations: {
max_size: {
max: {
field: size
}
}
total_size: {
sum: {
field: size
}
}
}
}
}
}
}
publish: [
{
stream: data
}
]
}
{
type: punch
component: punch
settings: {
punchlet_code:
'''
{
Tuple buckets;
convert(root:[source]).into(buckets);
buckets:/ = buckets:[aggregations][by_channel][buckets];
for (Tuple obj: buckets.asArray()) {
// this step is necessary as column names containing "." character is not well supported (Bad practice) in SQL query
obj = toFlatTuple().nestedSeparator("_").on(obj);
[key] = obj.getByKey("key");
[doc_count] = obj.getByKey("doc_count");
[max_size] = obj.getByKey("max_size_value");
[total_size] = obj.getByKey("total_size_value");
}
}
'''
output_columns: [
{
type: string
field: key
}
{
type: string
field: doc_count
}
{
type: string
field: max_size
}
{
type: string
field: total_size
}
]
}
subscribe: [
{
component: input
stream: data
}
]
publish:[
{
stream: data
}
]
}
{
type: sql
component: sql
settings: {
statement: SELECT key, doc_count, max_size, total_size, current_timestamp() AS timestamp FROM punch_data
}
subscribe: [
{
component: punch
stream: data
}
]
publish: [
{
stream: data
}
]
}
{
type: elastic_output
component: output
settings: {
index: apache_aggregation_metrics
nodes: [
{
host: localhost
port: 9200
}
]
}
subscribe: [
{
component: sql
stream: data
}
]
}
]
}
An aggregation made without the need of a Punch Node...
{
type: punchline
version: "6.0"
runtime: spark
tenant: default
dag: [
{
component: input
publish: [
{
stream: data
}
]
settings: {
aggregation: true
index: mytenant-events*
nodes: [
localhost
]
query: {
aggregations: {
by_channel: {
aggregations: {
max_size: {
max: {
field: size
}
}
total_size: {
sum: {
field: size
}
}
}
terms: {
field: vendor
}
}
}
query: {
bool: {
must: [
{
range: {
@timestamp: {
gte: now-1h
lt: now
}
}
}
]
}
}
size: 0
}
}
type: elastic_input
}
{
type: sql
component: sql
settings: {
statement: SELECT aggregation_result.doc_count, aggregation_result.key, aggregation_result.max_size.value AS max_size, aggregation_result.total_size.value AS total_size, doc_count_error_upper_bound, sum_other_doc_count FROM (SELECT explode(buckets) AS aggregation_result, doc_count_error_upper_bound, sum_other_doc_count FROM input_data)
}
subscribe: [
{
component: input
stream: data
}
]
publish: [
{
stream: data
}
]
}
{
component: show
subscribe: [
{
component: sql
stream: data
}
]
type: show
}
]
}
Warning
By default, Elasticsearch supports field names containing "dot" or "." character. Which is not the case in the SQL world. It is even consider as a bad practice. It is not recommended to use column name containing "." characters for executing Spark Sql queries.