Data extraction plugin¶
The Data Extraction plugin makes it possible to extract data from Elasticsearch.
It requires the Punch Gateway to launch an extraction job in the background.
Installation¶
The plugin dataExtraction-X.Y.Z.zip is available in the Standalone and in the Deployer.
bash $KIBANA_INSTALL_DIR/bin/kibana-plugin install file:///<path-to-dataExtraction-X.Y.Z.zip>
Configuration¶
The plugin has the following parameters in $KIBANA_INSTALL_DIR/config/kibana.yml
# Mandatory
data_extraction.api.hosts: ["http://localhost:4242"]
data_extraction.tenant: mytenant
# Optional with default values
data_extraction.enabled: true
data_extraction.useLegacy: false
data_extraction.api.ssl.enabled: false
data_extraction.api.ssl.certificateAuthorities: [""]
data_extraction.api.ssl.certificate: ""
data_extraction.api.ssl.key: ""
Usage¶
Display extractions¶
Click on the Data extraction tile in Kibana.
All extractions created are displayed on this screen.
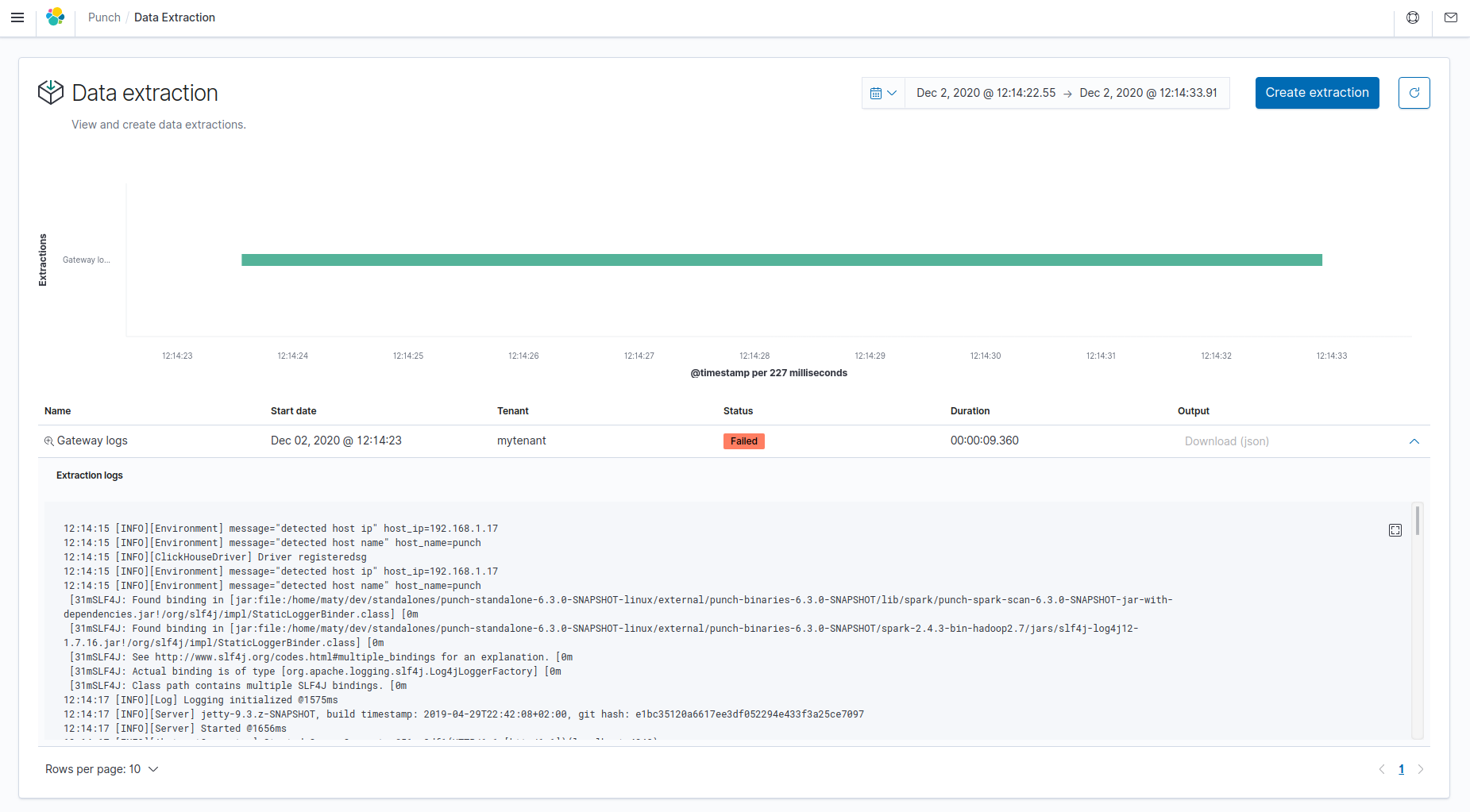
You can see extraction information like description, current status, duration and output location.
- Status: Available status are Scheduled, Submitted, Running, Success, Failed.
- Output: You can download file directly. It will be an archive containing multiple files (in CSV or NDJSON).
- Logs: Click on the arrow at the right to toggle the display of its logs.
You can manually refresh the extractions by refreshing the whole page.
Create an extraction¶
Before you create an extraction
Make sure :
- This Punch Plugin instance is connected to a Punch Gateway.
- This Punch Gateway is connected to an ES data cluster.
- The data you try to extract are located inside this ES data cluster.
- You have at least a
Saved searchor anIndex Patternin Kibana. - Punch template
pp_mapping_metadata.jsonhas been pushed to ES clusters.
To create a new extraction, click on Create extraction at the top of the page.
Fill in the fields

- Kibana saved search: Select from which save search (made from Discover) to extract the data
- Extraction range: Select date range
- Max size: Set maximum output rows
- Extract _id: Check to add a column
idwhich contains Elasticsearch document_id - Extract all fields: Check to add a column
sourcewhich contains Elasticsearch document_source - Fields to extract: Select fields you want in your subset. Click
on the field to put it into the other column. The available fields
are on the left, the selected fields are on the right.
TIPS: Use arrows between columns to move all from left to right and vice-versa. - Filters: Add filters on your extract data
- Description: Name your extraction
- Output format: Choose where to extract, in another Elasticsearch index, or in file (CSV/JSON)
- Separator: For CSV format. Choose separator to delimit your columns in output.
- Headers: For CSV format. Include column headers in output.
- Tenant: Related to the Gateway tenant.
Change Runtime¶
Plugin Extraction is based on a Punch Topology. This topology can be run in Storm runtime (default) or in Spark runtime.
Plugin Extraction in Storm runtime is based on a Storm-like topology with : - Extraction Input - Punchlet Node to flatten tuples - File Output
Plugin Extraction in Spark runtime is based on a Spark-like topology with : - Elastic Input - File Output
To configure Plugin Extraction in Spark runtime, configure kibana.yml with :
data_extraction.useLegacy: true
Warning
Please note that Spark extraction requires data to fit in memory. If you want to extract massive amount of data, use Storm extraction instead.
Update extraction template¶
The topology to run extraction is based on a topology template.
This template is filled with the information provided in the Data Extraction plugin.
You can modify this template to fine tune your extraction.
Storm template:
$PUNCHPLATFORM_GATEWAY_INSTALL_DIR/templates/extraction/storm/extraction_es_to_file.yaml.j2
Spark template:
$PUNCHPLATFORM_GATEWAY_INSTALL_DIR/templates/extraction/spark/extraction_es_to_file.yaml.j2
Troubleshoot extraction¶
You can view templated topologies in the path configured in resources.manager.data.file.root_path + resources.punchlines_dir.
You can view extraction results in the path configured in resources.archives_dir.
Compatibility¶
| Plugin version / Punch version | 6.4.1 | 6.4.2 | 6.4.3 | 6.4.4 | 6.4.5 |
|---|---|---|---|---|---|
| 1.2.1 | included | yes | yes | yes | yes |
| 1.2.4 | yes | included | yes | yes | yes |
| 1.2.5 | yes | yes | included | included | included |
Legend
- yes : compatible
- no : not compatible
- included : included in Deployer & Standalone binaries