Kafka Output¶
The Kafka bolt writes data to a Kafka topic and automatically distribute the load between the topic partitions. It basically sends the content of storm tuples to Kafka brokers. Here is a simple example:
{
"type": "kafka_output",
"settings": {
"topic": "mytenant.apache",
"brokers": "front",
"encoding": "lumberjack",
"producer.acks": "all",
"producer.batch.size": 16384,
"producer.linger.ms": 5
}
}
You can configure the bolt using the many native Kafka producer settings. A complete example follows.
Warning
if the topic does not exists it will be created. Pay attention to the fact it will then have the default replication factor and partition number. Most often your topic is described in the channel configuration file where you can set these parameters explicitly. Even so the topic will only be created with these settings if you go through the channel start command.
Bottom line : If you only start a topology without the topic be created first, your topic will have the default settings.
Parameters¶
Critical parameters¶
producer.acks: Integer
- The number of acknowledgments the producer requires the leader to have received before considering a request complete. This controls the durability of records that are sent. The following settings are allowed:
- acks=0 If set to zero then the producer will not wait for any acknowledgment from the server at all. The record will be immediately added to the socket buffer and considered sent. No guarantee can be made that the server has received the record in this case, and the retries configuration will not take effect (as the client won't generally know of any failures). The offset given back for each record will always be set to -1.
- acks=1 This will mean the leader will write the record to its local log but will respond without awaiting full acknowledgement from all followers. In this case should the leader fail immediately after acknowledging the record but before the followers have replicated it then the record will be lost.
- acks=all This means the leader will wait for the full set of in-sync replicas to acknowledge the record. This guarantees that the record will not be lost as long as at least one in-sync replica remains alive. This is the strongest available guarantee. This is equivalent to the acks=-1 setting.
producer.batch.size: Integer
- The producer will attempt to batch records together into fewer requests whenever multiple records are being sent to the same partition. This helps performance on both the client and the server. This configuration controls the default batch size in bytes. No attempt will be made to batch records larger than this size. This setting defaults to 16384
- Requests sent to brokers will contain multiple batches, one for each partition with data available to be sent.
- A small batch size will make batching less common and may reduce throughput (a batch size of zero will disable batching entirely). A very large batch size may use memory a bit more wastefully as we will always allocate a buffer of the specified batch size in anticipation of additional records.
producer.linger.ms: Integer
- The producer groups together any records that arrive in between request transmissions into a single batched request. Normally this occurs only under load when records arrive faster than they can be sent out. However in some circumstances the client may want to reduce the number of requests even under moderate load. This setting accomplishes this by adding a small amount of artificial delay---that is, rather than immediately sending out a record the producer will wait for up to the given delay to allow other records to be sent so that the sends can be batched together. This can be thought of as analogous to Nagle's algorithm in TCP. This setting gives the upper bound on the delay for batching: once we get batch.size worth of records for a partition it will be sent immediately regardless of this setting, however if we have fewer than this many bytes accumulated for this partition we will 'linger' for the specified time waiting for more records to show up. This setting defaults to 5. Setting linger.ms=5, for example, would have the effect of reducing the number of requests sent but would add up to 5ms of latency to records sent in the absence of load.
Mandatory Parameters¶
topic: String
- The topic to send data to
brokers: String
- the kafka brokers, as defined in your $PUNCHPLATFORM_CONF_DIR/punchplatform.properties configuration file If
bootstrap.serversis set, this parameter is only used to define a metric id to identify your cluster in Punchplatform metrics
-
encoding: String-
lumberjack: one or several messages are encoded using a proprietary format. This mode makes it possible to monitor the Kafka queues not only using offset ranges but also using a time based view. This mode also allows you to group several messages in a single Kafka message so as to allow efficient compression and reduce io operations. -
json: messages are written to Kafka as Json string, with no transformation. Using this mode, messages are sent one by one to Kafka, i.e. all bulk related options will have no effect.
With the json encoding, you can select a single field to be written to Kafka. In that case the Kafka message will contain only that field value, not the key. To activate this use the following property
"payload_field" : "log" -
Optional Parameter¶
exit_on_kafka_failure: Boolean
- enabled the fail-stop configuration of the kafka bolt. It is recommended to enable this feature in production.
bootstrap.servers: String
- Supersedes the values computed based on the
brokersparameter. If present, it will override the default brokers addresses/ports from punchplatform.properties to resolve your kafka cluster. Ex : "localhost:9092,otherhost:9092". This can be useful in some context where the kafka cluster is not addressed with the same names/addresses depending on the source machine (here, the one running the punchline), or in case of ports routing.
Security Parameters¶
-
producer.security.protocol: String- Security protocol to contact Kafka. Only
SSLis supported.
- Security protocol to contact Kafka. Only
-
producer.ssl.truststore.location: String- Path to client truststore to check Kafka SSL certificate.
-
producer.ssl.truststore.password: String- Password to open client truststore.
-
producer.ssl.keystore.location: String- Path to client keystore to send client certificate to Kafka SSL. Mandatory if client authentication is required in Kafka SSL configuration.
-
producer.ssl.keystore.password: String- Password to open client keystore. Mandatory if client authentication is required in Kafka SSL configuration.
Partitions load-balancing¶
Let's take a simple example to explain the partition load-balancing concept. You have input data containing user's name and job, it looks like:
[
{
"username": "alice",
"job": "architect"
},
{
"username": "bob",
"group": "biologist"
},
...
]
If you are using a topic with 3 partitions, message are stored using the
default round-robin strategy (i.e. the 1st message goes in partition 0,
the 2nd in partition 1, the 3rd in partition 2, the 4th in partition 0 and
so on). Now, let's say you want to regroup user with the same job in
the same partition. Use the partition_key optional field to achieve
this, your configuration should look like this one:
{
"type": "kafka_output",
"settings": {
...
"partition_key": "job",
...
},
"storm_settings": {
...
}
}
Java Documentation¶
The KafkaBolt javadoc documentation provides a detailed description of each property.
Example¶
Here is a typical configuration example:
{
"type": "kafka_output",
"settings": {
"topic": "mytenant.apache",
"brokers": "front",
"encoding": "lumberjack",
"producer.acks": "all",
"producer.batch.size": 16384,
"producer.linger.ms": 5
}
}
It is also possible to configure the KafkaBolt to receive documents from multiple Storm streams, in a way to dispatch them to different topics. In this case, the setting must be replaced by a list named :
[...]
"topics": [
{
"stream": "flow1",
"topic": "destination-1"
},
{
"stream": "flow2",
"topic": "destination-12
}
]
Streams and Fields understanding¶
The Kafka bolt subscribes to a stream, and put all the received fields inside a serialized map of key values. The binary encoding format is configurable. As of today Json or Lumberjack are supported. The field names are thus encoded as part of the message, and will be extracted by a downstream KafkaInput.
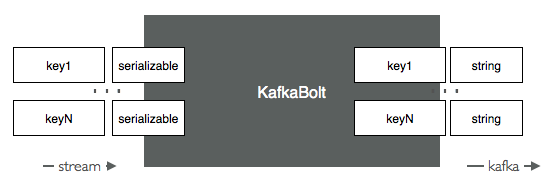
Refer to the KafkaBolt javadoc documentation.
Writing Data To A Third-Party Kafka Cluster¶
A Kafka bolt can write data to an external third-party Kafka cluster. This is typically used to publish interesting events to a third party correlation or alerting application. To do that you must add a section in your punchplatform.properties file and set there the target kafka settings. Here is an example:
"remote": {
"my-external-system": {
"kafka": {
"clusters": {
"kafka-alerting": {
"brokers": [
"x.y.z.t:9092"
]
}
}
}
}
}
With such a configuration you can have your KafkaBolt publishing data to your external broker by using the [remote] property as follows:
{
"type": "kafka_input",
"settings": {
...
"remote": "my-external-system",
"brokers": "kafka-alerting",
...
},
"storm_settings": {
...
}
}
Make sure you know what format is expected from the external Kafka. It is unlikely is supports the proprietary Lumberjack format used by the PunchPlatform. Most likely you will have to publish using the encoding.
Metrics¶
See metrics_kafka_bolt