Overview¶
Abstract
The Punch lets you define you complete platform and applications using simple configuration files. These files are structured in a simple and straight per tenant then per channel layout. In there every data processing pipeline, every administrative task is defined as part of a tenant. In each tenant, you further organize your processing units into channels. A channel is a set of task, each defined as a punchline.
Channels may also contain administrative tasks to provide you with your data lifecycle configuration, or third party components such as logstash, or even yours. Whatever mixture of punchlines or third party components you group in a channel,
Concepts¶
Here is a quick recap of the basics. Every business or administrative application is defined as part of a tenant. In each tenant, you further organize your processing units into channels. A channel is a thus a set of applications that you can start or stop alltogether.
More precisely Punch applications can be:
- punchlines: these cover streaming or batch data processing pipelines. The punch supports various runtime engines for these.
- Additional ready-to-use punch application, for example for taking care of data housekeeping.
- Third-party applications such as ElastAlert or logstash, fully integrated for you in the Punch.
- Your own applications.
Architecture¶
Here is the overall view of how the punch allows a user to submit different types of applications to various processing engines.
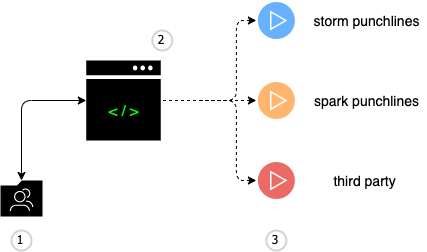
where:
- is a (typically) shared folder equipped with revision control capabilities. This repository contains all the platform and application configuration files.
- represents an administrative console for the sake of illustrating how a terminal user can start an application.
- are (typical) examples of applications launched and managed by the punch.
- a storm punchline used for streaming use cases
- a spark punchline used for batch or streaming analytics processing
- a third-party application. An example is a logstash process, it could be your own.
Configuration¶
Here is the layout of a punch platform configuration tree.
└── conf
├── resources
│ ├── elasticsearch
│ │ ├── templates
│ │ └── example_requests
│ └── kibana
│ ├── dashboards
│ ├── cyber
│ ├── other
│ └── platform
└── tenants
├── customer1
│ └── channels
│ │ ├── admin
│ │ │ ├── channel_structure.hjson
│ │ │ └── housekeeping_punchline.hjson
│ │ └── apache_httpd
│ │ ├── archiving_punchline.hjson
│ │ ├── channel_structure.hjson
│ │ └── parsing_punchline.hjson
│ └── resources
│ └── punch
│ └── punchlets
│ ├── apache_httpd
│ │ ├── enrichment.punch
│ │ ├── http_codes.json
│ │ ├── normalization.punch
│ │ ├── parsing.punch
│ │ └── taxonomy.json
│ └── common
│ ├── geoip.punch
│ ├── input.punch
│ ├── parsing_syslog_header.punch
│ └── printroot.punch
└── platform
├── channels
│ ├── housekeeping
│ │ ├── channel_structure.hjson
│ │ └── elasticsearch-housekeeping.json
│ └── monitoring
│ ├── channels_monitoring.json
│ ├── channel_structure.hjson
│ ├── local_events_dispatcher.hjson
│ └── platform_health.json
└── resources
└── punch
└── standard
└── Platform
└── monitoring_dispatcher.punch
confis here a sample of a root folder where all configuration files are stored in the punch operator command-line environment. The location of that folder is defined in the $PUNCHPLATFORM_CONF_DIR environment variable.tenantscontains your per-tenant configurations. Remember everything is defined in a tenant.- the reserved
platformtenant is used for platform level applications. Some monitoring or housekeeping tasks are typically defined at that level. End user do not have access to this tenant (different Elastic indices & Kibana), only the platform administrators. - here the
customer1tenant is a fictive end user example. - each tenant has a few additional properties defined in the
etc/conf.jsonfolder. resourcescontain various per tenant shared resources. Think of parsers, enrichment files, machine learning models, kibana generic dashboards. This folder is shared among the various channels from that tenant.
- the reserved
channelsall applications are grouped in ways you decide in channels.channel_structure.hjsoneach channel (for instance 'admin' or 'apache_httpd') is defined using this file. It basically defines the channel content.punchlines.hjsonindividual applications are defined by punchlines.
In reality you can have more applications than sketched out here, including third-party apps. But this minimal description suffices for you to understand the punch configuration structure.
Tip
On simple platforms this conf directory is the top-level root folder holding all the files. On some production
platforms the configuration can be partly stored on the filesystem, and partly stored on some 'resources backend' and exposed through the REST punch gateway API.
This is especially the case when some resources can be updated dynamically by outside processses (like enrichment dictionaries or Threat-intel markers tables)
A key benefit of the punch is to keep all this extra simple : you essentially deal with the configuration files to fully define your tenants, channels and application scheduling policies. In the rest of this chapter we provide several examples of the right part in order for you to understand how applications are submitted, stopped and monitored.
Warning
Some of the platform resources (ES index templates/mappings, Kibana dashboards) are not applied automatically during platform components deployment. Thus you must import them manually by following this guide
Propagation of the operator configuration¶
The configuration tree exists in the punch operator session. Each time an application is submitted to the Punch clusters for execution, it will need access to part of the files from this configuration tree (especially resource files, punchline files), in a consistent state (the one desired by the operator).
This is taken care of by the punch framework:
For that, the punch uses a persistent store to keep track of running applications and their configuration tree snapshot.
Storm cluster punchline submission¶
The configuration is stored inside a submitted job package (serialized in a jarfile), and uploaded to the storm cluster (first the 'masters' (nimbus) cluster, then later the 'slave' node (storm supervisor) that will run the punchline. This configuration is therefore immutable during the lifetime of the application submission (i.e. until an operator stops and restarts the application again). An exception: if the punchline refers to resource stored in an url-accessible resource back-end, then dynamic reload of new resource versions is possible without the application restart by an operator.
Standalone Punch shiva application submission¶
The standalone punch is a single-node easy setup that you can install and run in minutes. It is also a good example of a simple yet effective architecture to illustrate all the required production-grade services yet running on a minimal footprint. Here is how the standalone application control and monitoring plane is implemented on a standalone to communicate commands and operator configuration to the runtime environment.
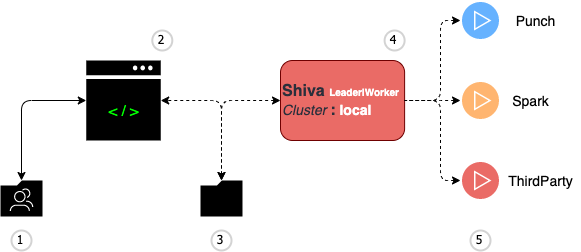
With this simple setup the local filesystem is used.
The administration store is also used to request application start or stop commands. A punch daemon called shiva is in charge of
executing the applications.
application submission to a distributed shiva cluster¶
A production punch requires a high-available administration store. Instead of using the local filesystem, kafka is used to provide the required
storage engine for commands and operator configuration snapshots. This is illustrated next :
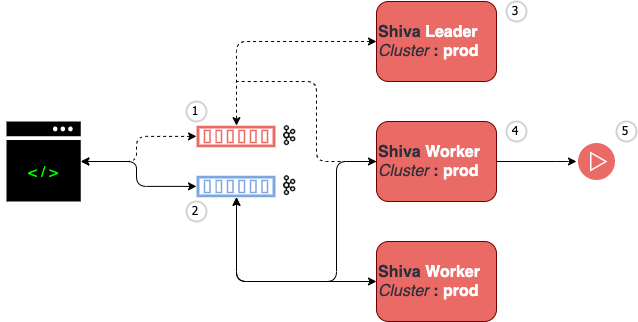
- the configuration folder is on the operator local filesystem. It is located in the installation directory
conffolder. - operator is using hisr (linux|macos) terminal to issue administrative command (e.g. application or channels submission)
- in the Kafka cluster, three topics are used :
- (4) standalone-shiva-ctl for scheduling applications to shiva
- (5) standalone-shiva-data for scheduling applications to shiva
- (6) standalone-admin to retain the current application(s) status
- a shiva cluster : this is the punch proprietary application scheduler.
- a spark cluster to run spark and pyspark applications.
- a storm cluster to run streaming punch processing applications.
The configuration is stored inside a configuration snapshot, sent through Kafka to the shiva cluster. The runner node will extract this snapshot to provide a consistent configuration view to the punchline when it runs on the shiva runner node.
This configuration is therefore immutable during the lifetime of the application submission (i.e. until an operator stops and restarts the application again). An exception: if the punchline refers to resource stored in an url-accessible resource back-end, then dynamic reload of new resource versions is possible without the application restart by an operator.
Platform Properties (generated file)¶
The applications and punch components often need to know the layout/functions of the platform servers.
The punchplatform.properties file is generated during deployment time, based on the punchplatform-deployment.settings configuration file provided to the deployer tool. The punchplatform.properties is deployed on the various platform nodes that need this information.
This file holds essential informations required by punch components to interact with each other ; it can also be viewed by the operator to better understand the platform structure, and easily locate services when investigating incidents.
In an operator environment, the file is pointed by $PUNCHPLATFORM_PROPERTIES_FILE environment variable.
Here is an example from the standalone punchplatform :
"platform" : {
"platform_id" : "my-unique-platform-id",
"admin" : {
"type": "kafka",
"cluster" : "local",
"topics" : {
"admin_topic" : {
"name" : "standalone-admin"
}
}
}
},
"kafka" : {
"clusters" : {
"local" : {
"brokers_with_ids" : [ { "id" : 0, "broker" : "localhost:9092" } ],
}
}
},
"shiva": {
"clusters" : {
"platform" : {
"type" : "kafka",
"cluster" : "local",
"topics" : {
"control_topic" : {
"name" : "standalone-shiva-ctl"
},
"data_topic" : {
"name" : "standalone-shiva-data"
}
}
}
}
}
}
Tip
The punchplatform is highly modular and lightweight. Here the example platform has only the internal punch application scheduler called shiva that allows the execution of many simple and useful applications such as logstash, punch lightweigth pipelines or you own python application. Of course you can configure it with more components such as a Spark, Storm engine, plus Elasticsearch. It all depends on your use case but the principles are the same.
This file is distributed on platform servers holding Shiva, Gateway and Operator components and located in each associated package. Check component's documentation to have more details
Resolver¶
The resolv.hjson file may contain some precious informations used by the operator, the gateway and shiva components at runtime. It supersedes information
from your application and channels, to adapt them for the actual platform if needed.
This file is prepared by the integration, and deployed alongside the punchplatform.properties file on all requiring nodes of the platform.
In an operator environment, a copy of this file is pointed by $PUNCHPLATFORM_RESOLV_FILE environment variable.
Check this documentation to have a full description of this file and how it works.
Here is an example from the standalone punchplatform :
{
// All ES input/output nodes (Storm nodes)
elasticsearch_nodes:{
selection:{
tenant:*
channel:*
runtime:*
}
match:$.dag[?(@.type=='elasticsearch_output' || @.type=='elastic_output')].settings
additional_values:{
http_hosts:[
{
host:localhost
port:9200
}
]
}
}
// All ES spark nodes
elastic_nodes:{
selection:{
tenant:*
channel:*
runtime:*
}
match:$.dag[?(@.type=='elastic_input' || @.type=='elastic_query_stats' || @.type=='python_elastic_input' || @.type=='python_elastic_output' || @.type=='extraction_input')].settings
additional_values:{
nodes:[
localhost
]
}
}
}
This file is required for Shiva, Gateway and Operator components and located in each associated package. Check component's documentation to have more details.