A Punch Business and Functional Perspective¶
Why the Punch ?¶
A Brief Punch History¶
The punch is now a rich and robust Thales Service Numérique asset. It did not appear from nowhere.
Here is its short history:
Display the following image in full screen in an other tab to see the punch functional evolution
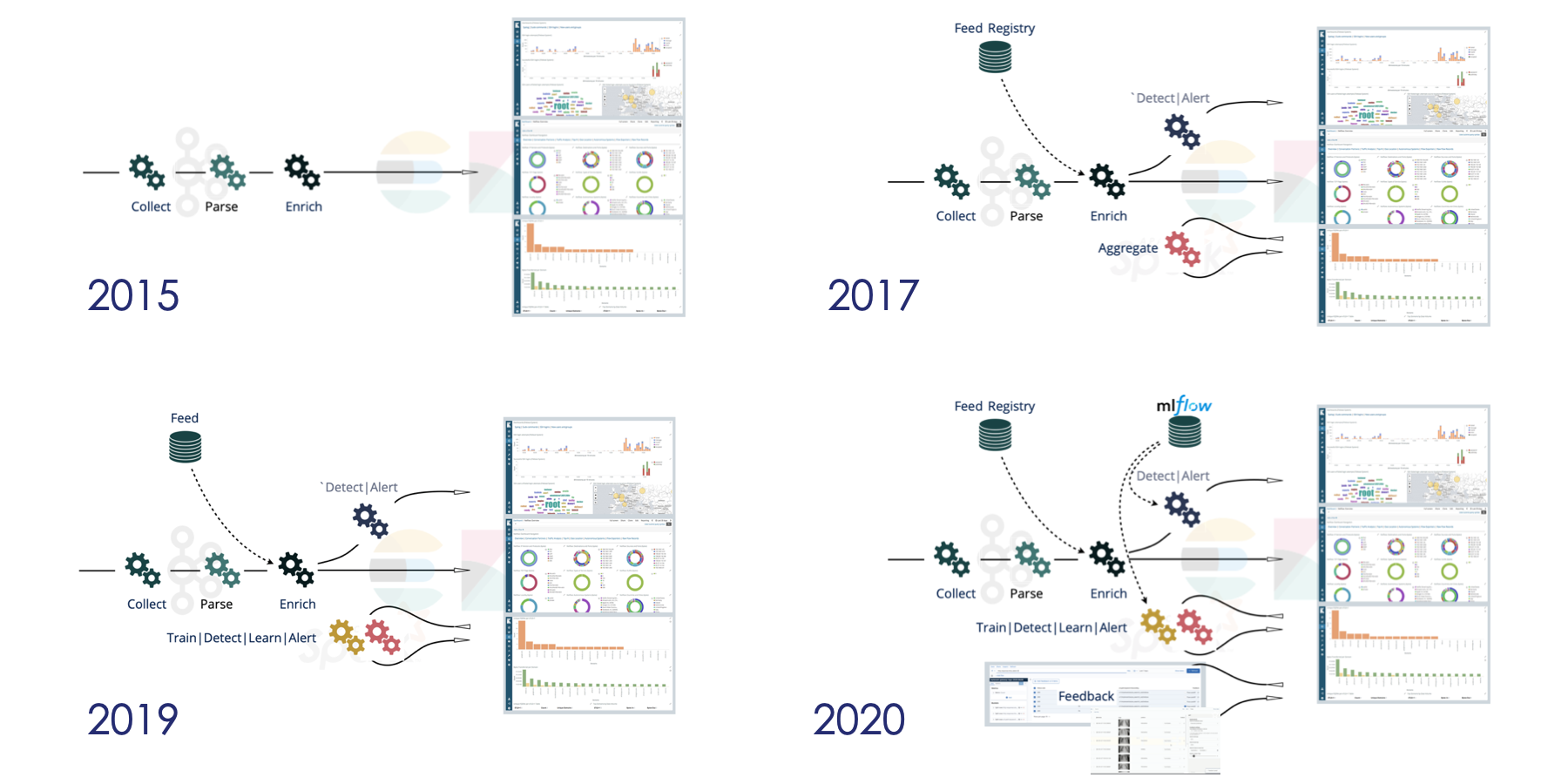
-
The punch was initiated in 2014. Its primary goal was to provide scalable and state-of-the art log management capabilities. The point was to replace some commercial or open source solutions that suffered from scalibility issues, and/or licnesing and cost issues. The two are often correlated as more traffic leads to ,ore expensive license costs.
-
The punch went to production in 2015. To succeed that first important milesont, our effort were devoted to deploy real-time stream processing capabilities in an easy to install, run and monitor distribution. One of its main technical feature was the punch language: a compact document handling language to handle json-like data without heavy development tooling.
Key Points
- Thales wanted to break out of scalability issues with log storage and searching, without trading them too hastily with licensing costs
- Thales wanted to have a logs collection chain preventing loss of logs and easier to configure to obtain High Availability
- Thales wanted to make logs parsing easier to maintain, even for non-developers
-
Soon after, batch processing appeared to deal with aggregations, extractions, or data replays. After two years, four cybersecurity platforms were leveraging the punch.
Key Points
- The first aggregation use cases was to compute important KPIs needed for traffic monitoring or billing, to reduce the amount of saved various metrics.
- The second use case was to improve user experience when navigating the aggregated data. The goal is to pre-compute the important aggregations to offer a low response-time search.
- To support these aggregations with a simple configuration and declarative approach, we first built our own (python) tool.
-
We started working on machine learning in 2016. It took us some time to come up with machine learning enabled punchlines, a key punch features. In 2019 several important ML demos demonstrated the punch capabilities. We started to actively collaborate with thales data science teams and labs, and with the cybersecurity group. The latter decided to build a new SIEM product on top of the punch.
Key Points
- Machine learning were first using only the Spark java libraries (MLLib) in conjunction with Elasticsearch to store the data
- Spark also gave us a nice scalable aggregation implementation, and we started designing periodic spark batch jobs.
- Just like for streaming application, these jobs are defined using configuration only. This is on contrast to standard spark usage that require you to code each job.
-
In 2020, we kept collaborating with more data science teams so as to better tackle the AI to production issues: machine learning model management and monitoring, capturing user feedbacks, etc.. These features are now integrated in the official release, although they are often used in the labs with a simple standalone deployment.
Key Points
-
The worldwide Machine Learning wave reached the "production/industrial" part of its lifecycle. Operating in production was now required (Deployment, Metrics/Monitoring, configuration management, custom process integration)
-
The real production story of ML implies parameters/models building and testing iterations (models configuration management and lifecycle)
-
Punch Market and Business Usages¶
Why is the pucnh used in such diverse use cases as shown in the documentation (Browse quickly the Welcome page...) ?
Key points
- The punch addresses needs that are not specific to the logs management but to many other data-centric use-cases. This explains why sometimes we refer to the generic 'structured documents' concept, while in other places we refer to 'logs'. But the punch is really agnostic of the business case.
- In all cases you need a smart integration of many technologies to extract and create value from your data data
- In most case you need a solution that is not too tight to a specific hosting platform. The punch runs great on premise, on Cloud, or embedded on board of a ship. This is a real strength.
- All this said the punch does provide additions that are dedicated to CyberSecurity: parsers, toolkits, etc..
Not everyone is on Azure or AWS

Punch Figures¶
Is it used already ?
Yes. The punch has been running (continuously) for more than five year in a number of large scale platforms in France and abroad, with very limited downtime.
It is also used on smaller industrial or Iot monitoring systems. The punch is also used in OEM to build a cybersecurity Thales product.
Last, it is intensively used in various innovation AI and data analytics projects funded by Thales Service Numérique.
- 5 Years of expertise
- 15+ platforms instances in production in Europe, Asia and North America
- 260k+ events per seconds, including platforms running 100eps, 25Keps, 55Keps, 120Keps
- 20+ customers running or investigating Use Cases in multiple domains
- 40+ engineers within Thales mastering the platform for their Use Cases
- 25+ engineers within Thales trained over the last 2 years
- 55+ on the shelf example log parsers, already running in production
Important
As you can see, the punch has two facets:
On one hand, it is a robust, stable and supported solution that can equip long-term critical industrial systems.
On the other hand, it is a lighweight, easy to work with solution that provides state-of-the-art data analytics and AI features. That second punch is as important, as it is used by many projects to explore new use cases and applications.
Punch versus ELK¶
ELK is ElasticSearch Kibana Logstash popular solution. What can we do with a punch that is not already in ELK ?
Let us begin from the ELK Basics, and the ecosystem (Following architecture diagrams are coming from Elastic site
Basic local Collection: Beats and Elasticsearch¶
Beats are lightweight collectors. They send Json documents directly to an Elasticsearch.
Simple (if you just need the json fields and data model that these beats are sending).
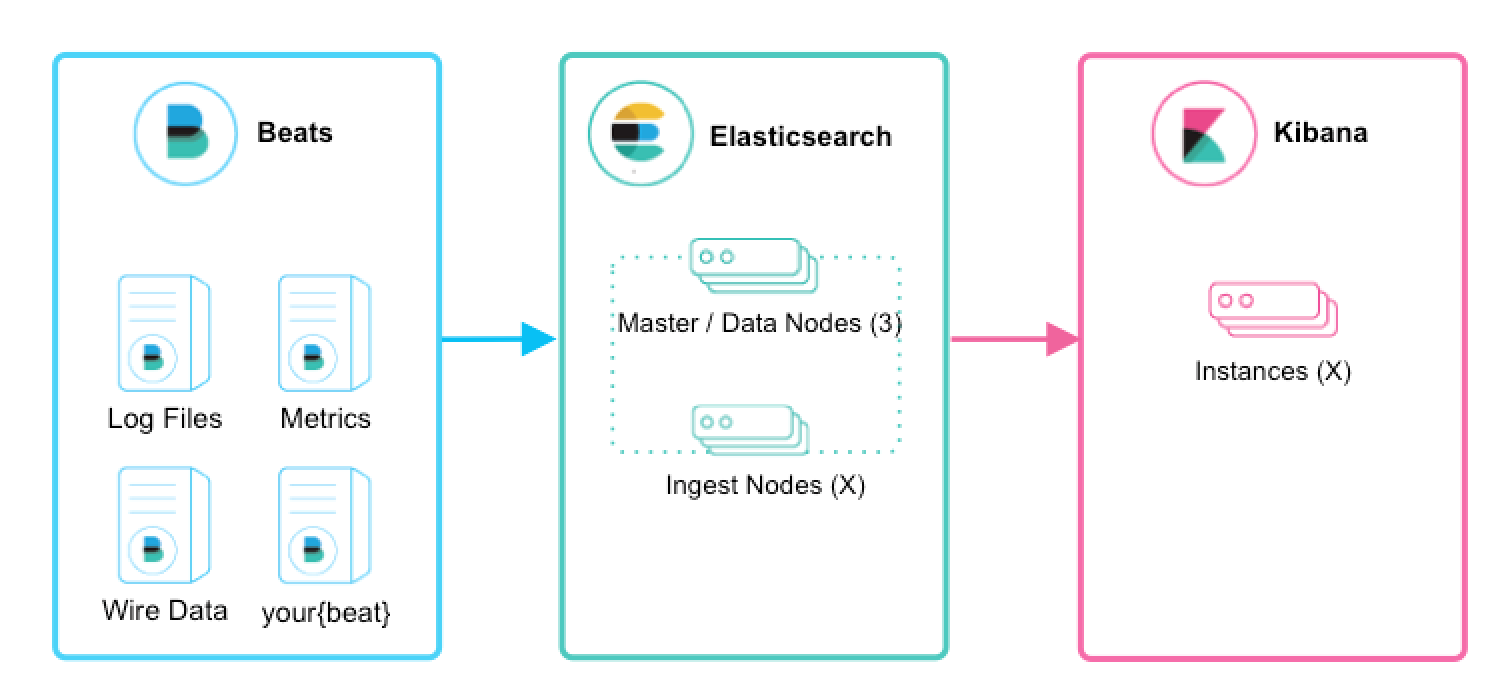
Key highlights
- The data model is imposed by each Beat, as no processing is done before indexing
- Direct connection from each beat to each indexing node is required. Static configuration needed for scalability.
- It works only with sources that push in json to Elastic API (i.e. almost only with Beats).
Collection with transport: Adding Logstash¶
When you need to move your logs accross connections, you need a lossless shipper. Logstash does that, with the Lumberjack protocol.
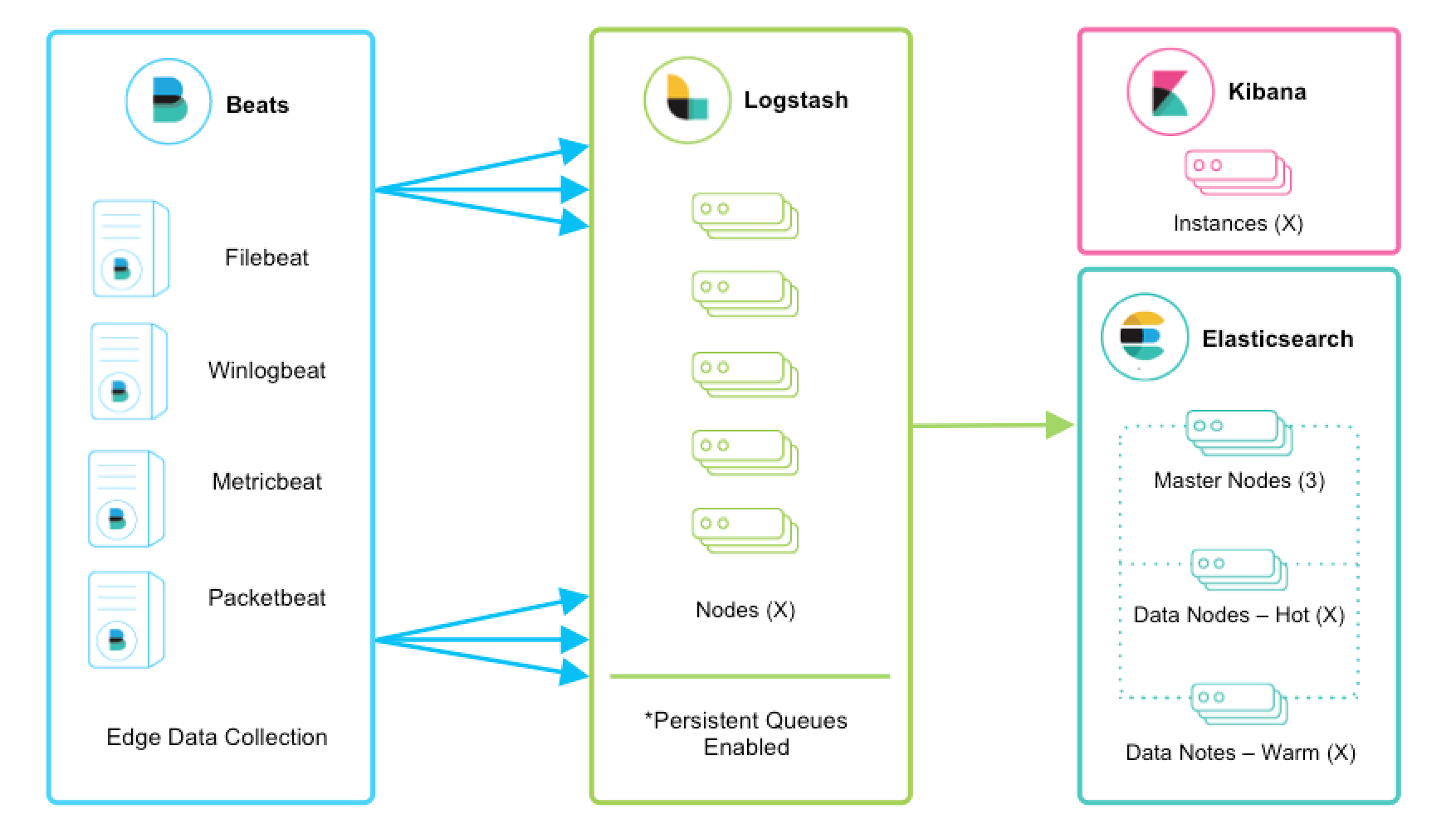
Key highlights
- logstash brings lossless transport between source and target, through the Open Lumberjack protocol that includes applicative acknowledgement
- this works only with sources that support the lumberjack protocol
Data Processing¶
Logstash brings streaming processing capabilities, bt mean of chaining successive filters.
Examples are grok patterns, dissect, mutate, and internal buffering.
Key highlights
- Logstash is not clustered by itself: the source Beats have to load-balance to the logstash nodes to allow load sharing, scalability and availability
- Logstash supports other kind of inputs (syslog over TCP/UDP...) but you have to plan for some load balancing if your source device is not smart enough
- As Retention is not clustered, in case of a logstash node loss with retention feature used, you may loose logs.
- you have to manage the configuration of multiple nodes consistently and monitor them (non-opensource Elastic features)
Resilience and Scalability: Kafka to the rescue¶
The widely used Kafka queuing system is used as a safe data-retention stage, and allows to scale processing by sharing the reading of same queues (topics)
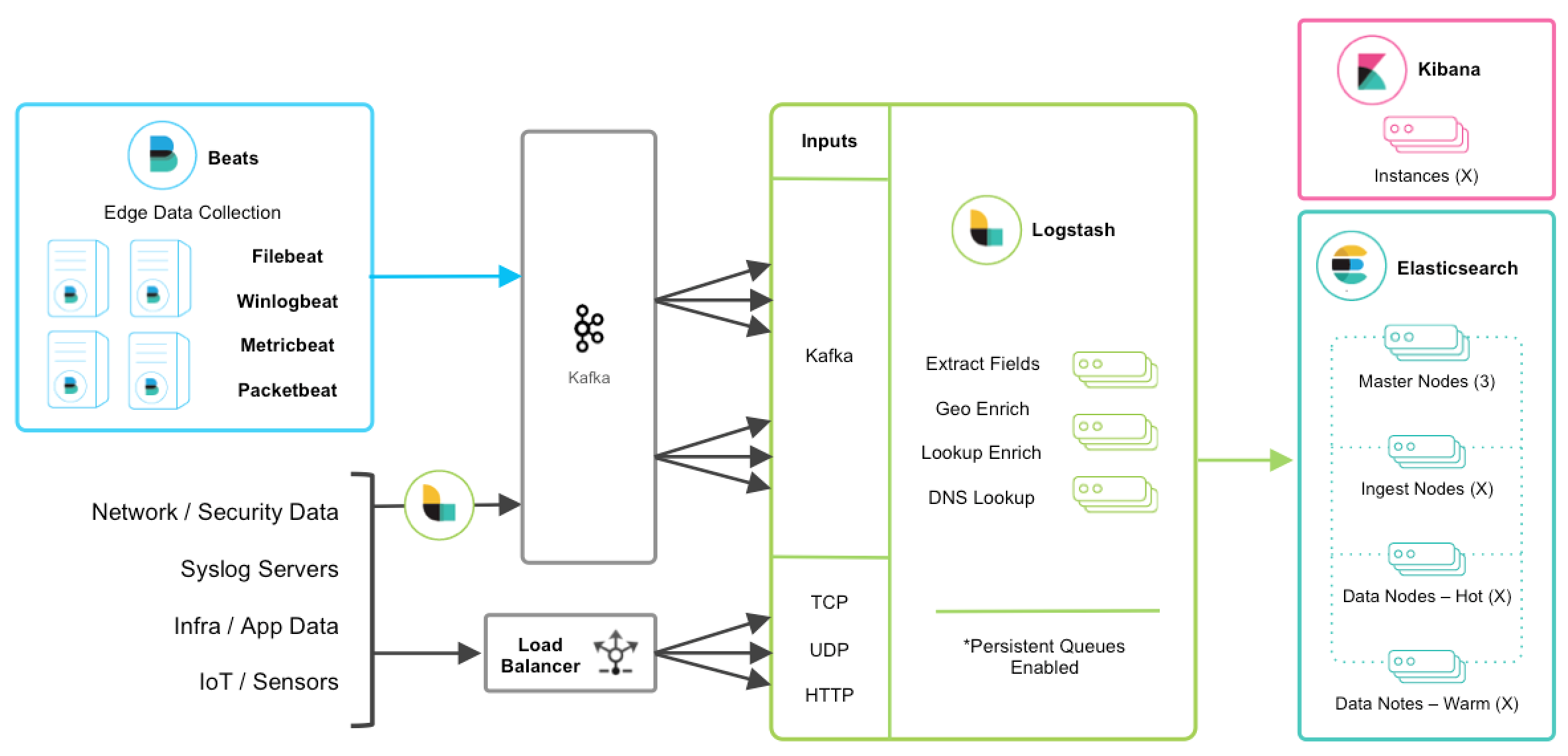
Key highlights
- Many device sources are not able to write logs directly to Kafka. A receiving stage is then deployed upfront to write to Kafka (see the second Logstash)
- You still have to manage consistently and monitor your Logstash nodes (more of them). In addition you have to configure and monitor your Kafka Cluster
Almost there.¶
But what about long term archiving, data purge automation, analytics batch processing, and the complex consistent configuration management and monitoring of all those additional beasts ?
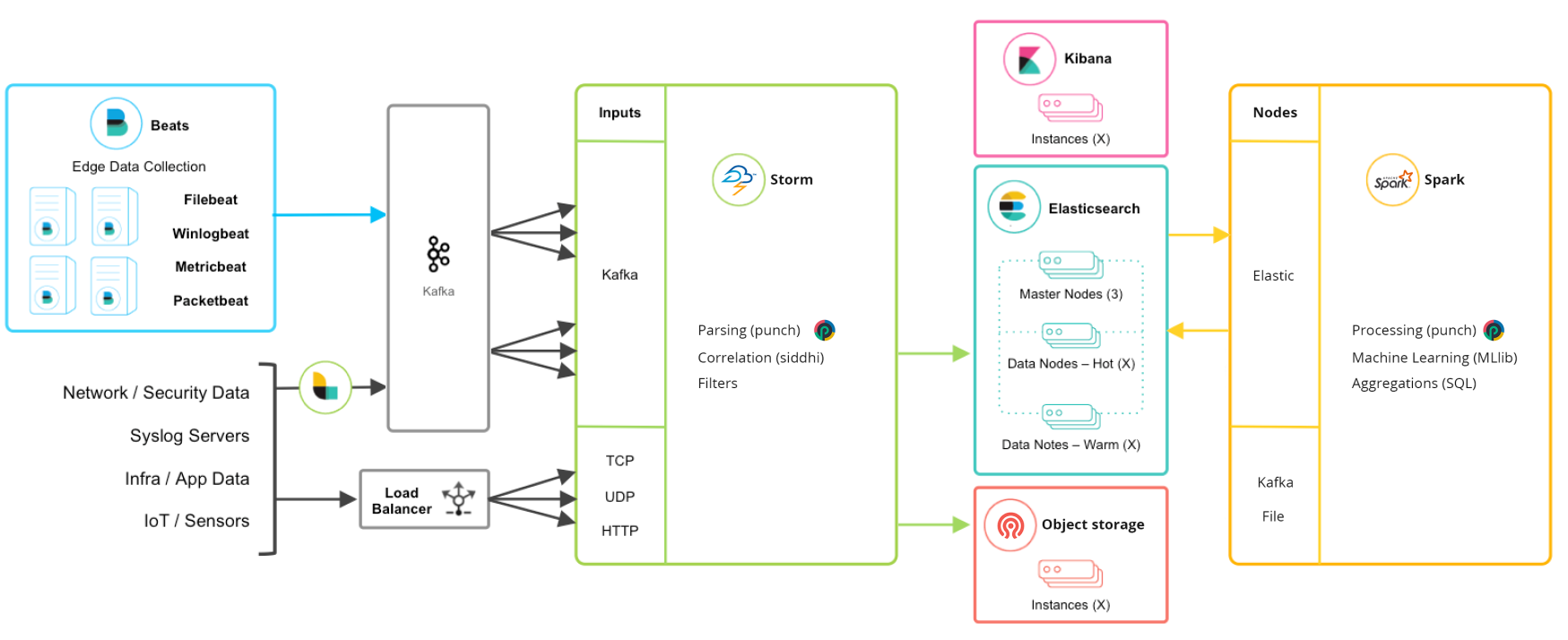
Here comes the Punch
- the processing cluster is now managed as ... a cluster where you can run many kind of applications (using Apache Storm Flink, Spark or the Punch Shiva scheduler)
- you can have custom enrichment or correlation processing tasks in the stream. Punchlang library includes usual operators (grok, dissect...) and many others. It is not verbose (easy to maintain pipelines) but also powerful (a true language, with access to all java libraries).
-
your applications and queues are set up through a centralized configuration of your pipelines and batches (easy configuration management and pipelines/rules/tasks deployment)
-
all the nodes you can use in the processing stage are lossless (at_least_once) with inbuilt error cases management and centralized metrics.
- among the punch processing components you have connectors for indexed archive storage (Ceph, shared filesystem like NFS, S3 API, CSV/Parquet/Avro formats)
- you can design batch processing, leveraging the SPARK technology for big data sets operation (Aggregations, complex joins, machine learning)
- among the provided packaged applications that can run in the cluster, Elastalert rule engine provides correlation/detection/notification capacity
- ALL this architecture is automatically monitored (metrics, health synthesis and API exposure) and housekeeped (data lifecycle management) through provided Punch micro-services
- Kafka, Spark, Ceph, Elastic, Kibana (and Even Logstash, if it brings useful specific input connectors) are still there, providing non-proprietary APIs for integrating in existing deployment or wider design.
Punch Capabilities and Features¶
Now we can understand punch architecture for data centric applications and the key capabilities it implies.
Key points
Depending on the context, required features and level of services/non-function requirements vary greatly:
- Industrial can mean 'no single point of failure' (HA) , 'secured' (Ciphered, lossless), 'multi-tenant' (data logical isolation, RBAC)
- Industrial can mean 'scalable to hundreds of machines with synthetic monitoring' or 'embedded on a small cluster of 3 servers' or even 'on one very small machine, in a single process'
- Industrial can mean 'platform with everyday managed changes of configuration, not requiring developers for maintainance/small evolutions' (configuration-driven, not code-driven)
- or 'portable centralized configuration, that is developed and validated by IVQ teams and can be transported easily between factory/integration platform and production sites'
And then take a tour of the various punch features and enablers.
Key points
-
all data centric/big data applications share the same needs and complexity of
- leveraging multiple widely used frameworks and technologies
- managing the configuration of all this zoo (platform deployment, pipelines, applications, scheduling, data model versionning...)
- managing the tradeof between mutualized platform capacity and logicial isolation between customers data sets (inter-tenants isolation)
- monitoring and keeping into working condition all this
-
punch is at the same time
- "the glue" (central configuration, standard monitoring services, deployer, custom nodes deployment and integration framework)
- a set of production-grade connectors (lossless, ciphering), processing nodes (including punchlang library) and tools (injector, performance testing, parser samples, CSV extraction plugin, pipelines designer)
A peek at Cybels Analytics Design and Features¶
The punch is also a component used as part of the Thales Cybels Analytics solution.
The Cybels Analytics brings in high-level analytics and cybersecurity features.
As an example, the Cybels Analytics Threat Detection/Log correlation feature brings:
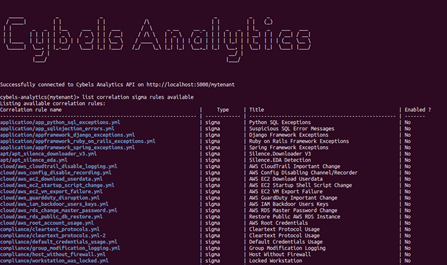 * Sigma rule management in command line (500+ existing rules for Windows, Sysmon, Linux, Cloud, Network environments…)
==> Activation/deactivation/conversion/configuration
* Sigma rule management in command line (500+ existing rules for Windows, Sysmon, Linux, Cloud, Network environments…)
==> Activation/deactivation/conversion/configuration
- Sigma templates management
- Advanced rules management for abnormal behavior detection
- spike detection (up and down)
- change detection (user authenticating from an unusual location)
- frequency detection (alert when the rate of an event exceeds a threshold, up or down)
- new term detection
- cardinality detection
- metric aggregation
- spike aggregation
- percentage match
- Advanced rule templates management
-
Alerts dashboard
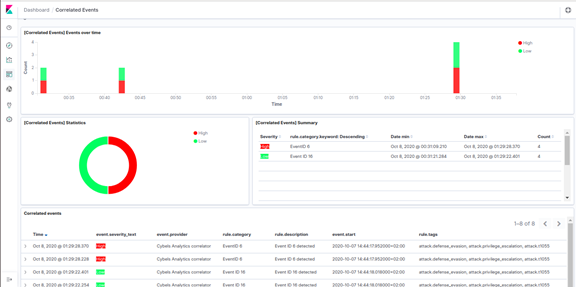
-
Alerting rule management (external notifications) Email, Zabbix, TheHive, HTTP Post, Custom script
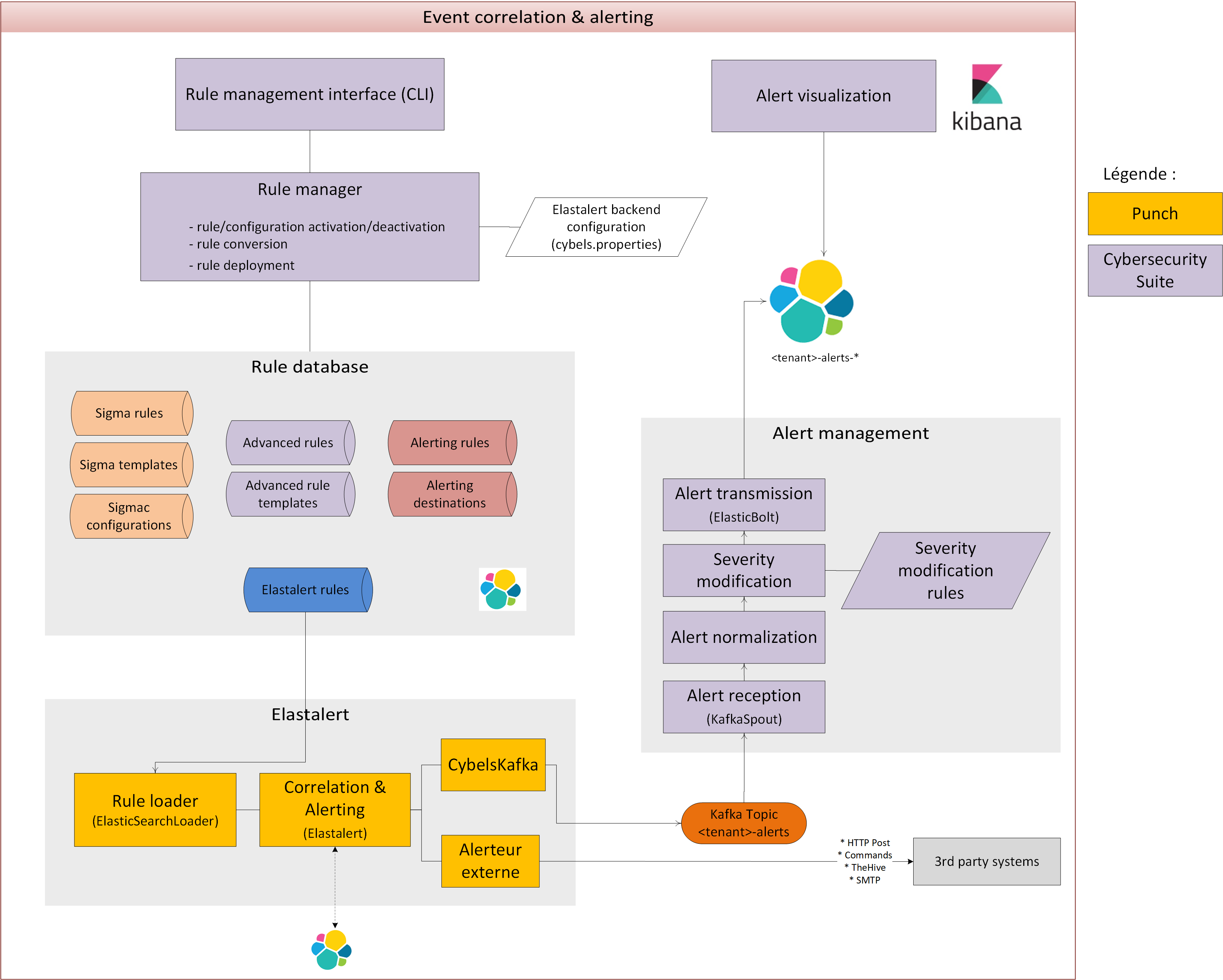
For this subset of Cybels Analytics design, here is a synthetic architecture of involved components:
The Punch Professional Services Team¶
The technical asset is important but far from being the main one. Years of retexes and expertise serving various production projects allowed us to build a complete service offering.
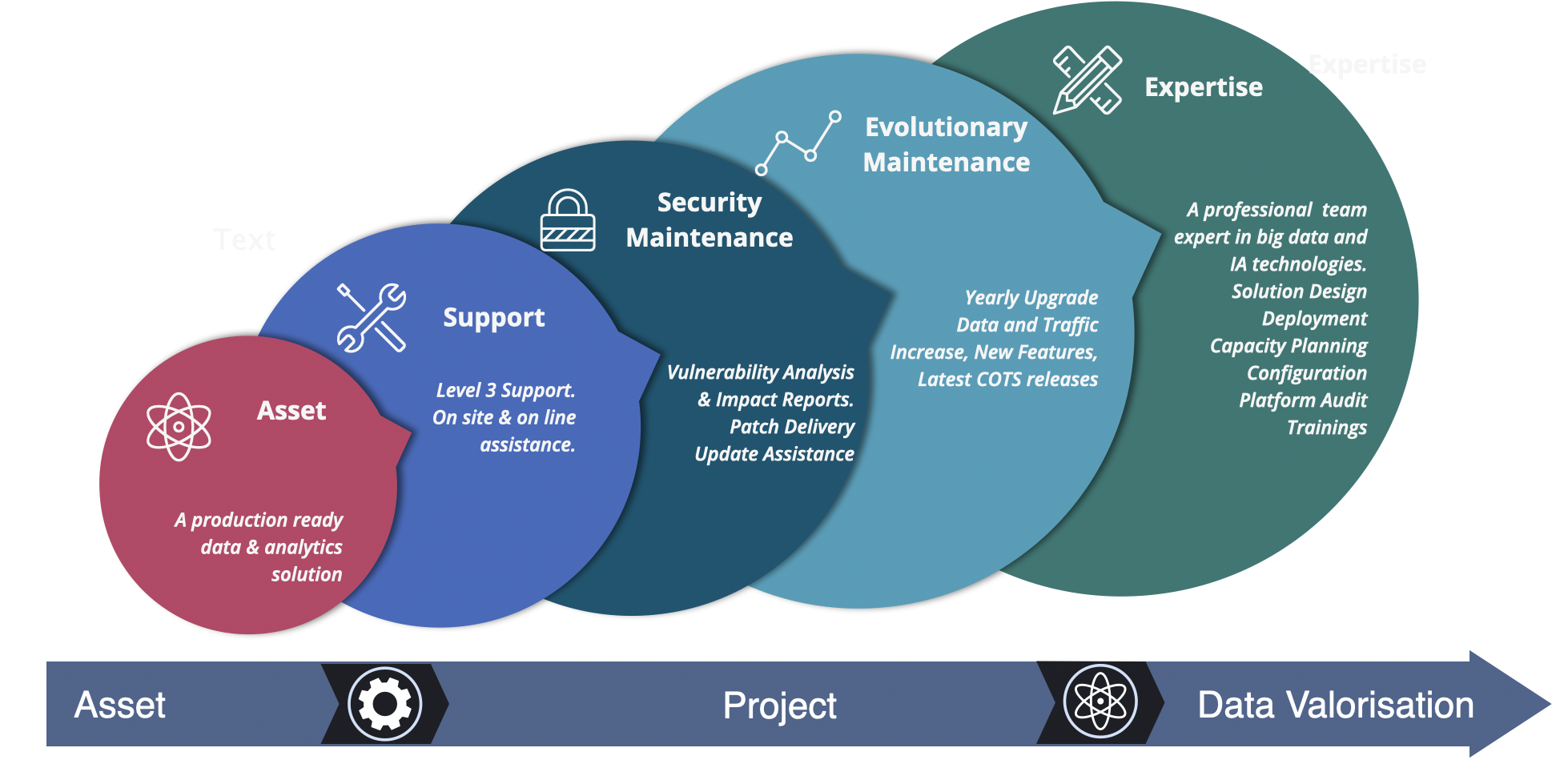 .
.
Checkout the punch professional service offering for details.
Understand the forward engineering Punch team offering
Often, the industrial process is not the usual 'V cycle' starting from the Specs or the Business case, but instead:
- collect your data
- view and get to know your data, try things (in lab, or best, near production area) because it is easy
- THEN clarify the services you want to sell, the added value you want to gain for your product or organization
- Refine a little bit your configuration, dashboards, hyperparameters of IA datamodel for customer usage
- it's cooked (you can run them on an integration or production platform)
And the Punch team can help you through this whole process.
Punch Business Value¶
Here are the Punch objectives:
- Reduce the platform build and operation costs.
- Quickly deliver values out of production data.
- Designed to start small, grow as needed, and only if needed. Small is beautiful too.
- The best of open source technologies, without requiring lots of costly integration and development work on top of it.
- Alleviate users and admin from plumbery issues and let them focus on their business use cases.
- Mutualise and share key components such as cybersecurity log parsers.
- Help projects on the long run, with yearly update/upgrade and support.
- Avoid or skip costly POCs or MVPS going ultimatly nowhere.
Is The Punch Free ?¶
No.
- True: the punch standalone is an easy to install punch release, free to download, not useable for production but has most features.
- True: the punchbox is an open source project that you are free to use to learn or test production-oriented punch deployments.
- True: training documentation is online and free to use.
But to go production, you need a license. That license allows the punch team to maintain the punch state-of-the-art, to provide you with support through our online help desk portal, and to proactively ship security patches.
Important
Having a production licence does not mean the Punch is heavy, cumbersome, or opaque: feel free to try the standalone punch, you can implement virtually all use cases on top of it. Train your own users using this material. All we ask for is for you to give us feedback to constantly improve our documentation and material.
Quizz¶
What kinds of use cases do you tackle using punch
1 2 | |
What is Punch ?
1 2 | |
What are the punch main characteristics ?
1 2 3 4 | |
What can you do with Punch ?
1 2 3 4 5 6 7 8 | |