Archiving¶
Abstract
Your data matters. Besides providing efficient online search over weeks or months of data, the punch also provide cost effective solutions to safely archive years of data, as well as extraction and reprocessing capabilities. This chapter highlights the design of the punch archiving features, and present the typical architectural setups.
Problem Statement¶
Using elasticsearch for archiving data is not the way to go. Even though it is compressed, indexed data takes room, and with full replication it quickly becomes too expensive. Besides, Elasticsearch is not a great fit to perform massive data extraction that are usually required for log management solutions.
Every elasticsearch user quickly faces the dilemma to place its cursor between online and cold data. If long term online search is required, one way to go is to keep only the first few days|weeks|months of elasticsearch data fully replicated, possibly keeping more data unreplicated. In case of failure, data will be lost but could be recovered from cold storage. Not be last that many critical application required cold and secured storage anyway. This overall dilemma is illustrated next.

The punch provides archiving connectors to save logs to object or filesystem storage, and housekeeping services to cleanup expired data. Whatever be your use case, you will be able to design a cost effective solution. Here are the two typical setups you can implement on top of the punch.
Scale Out Storage¶
The punch can archive data to the most standard scale out storage solutions, on cloud or on premise. Here is the principle architecture:
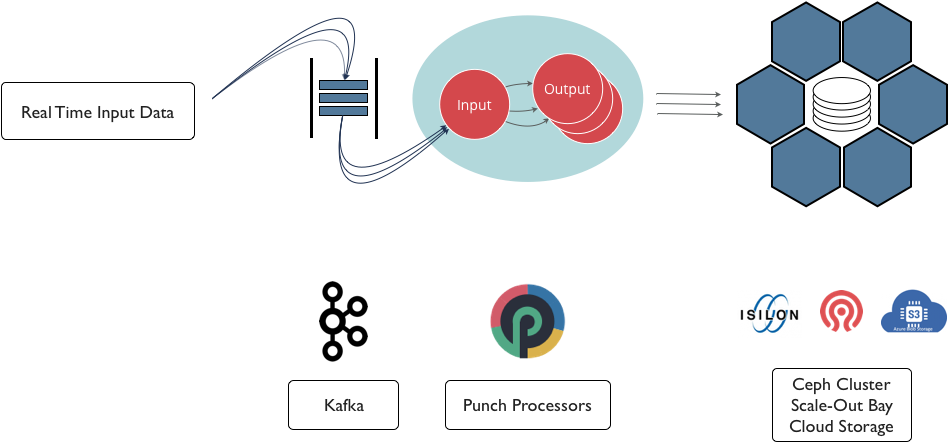
The benefits are:
- Cost effective : storage solutions such as Ceph or Isilon provide efficient erasure coding strategies to reduce the replication costs.
- Scalability : by design
- On Cloud or On premise : what matters are performance, idempotence and reliability. Those are provided by the punch IO connectors to consume Kafka data and ingest it to your storage solution using battle test batching components.
- On commodity hardware or on your storage scale-out bays : the punch is used in production on both variants
Warning
on the downside, note that leveraging erasure coding strategies has a strong impact on data restoration time. It can takes hours|days|weeks for a large cluster to reorganise the data after some node failed or after bringing in new nodes. This must be anticipated as it has a strong impact on your operations.
Commodity Servers¶
An alternative solution is to setup a simple yet robust system using a pair of standard servers. What is usually tricky using servers on your own is to achieve the same level of reliability and correctly coping with failure and reconciliation after failures. Using a CEPH or a storage bay has the advantage of resolving these issues for you.
It is however possible to achieve an equivalent solution by combining punch archiving processors and commodity servers as follows:
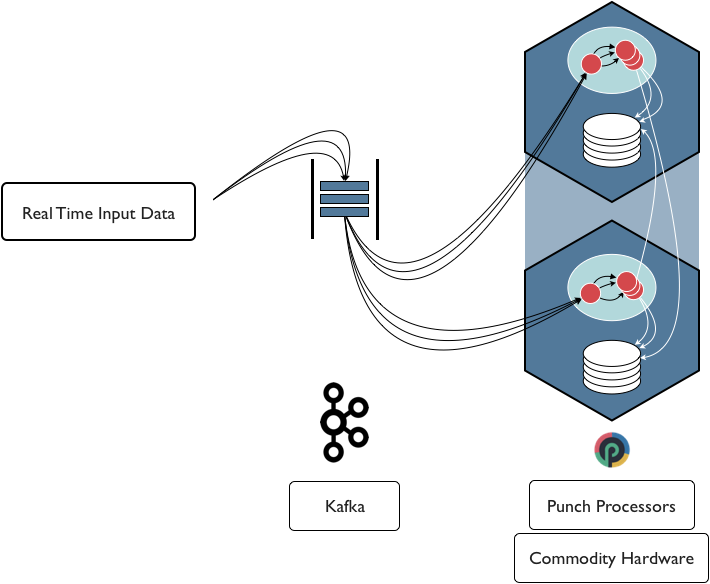
Refer to the reference guide for the detail of the punch pipelines at play here. This scheme has many benefits as well:
- simple to setup and operate
- easy to secure, in particular it can be deployed in a separated security zone.
- The data can be safely exposed using read-only access
- The pull ingestion scheme makes it hard for attackers to compromise the data ingestion
Warning
the only downside of this strategy is it requires a manual interventation should one of the two server fail. Say server 2 is out of state for a few days, when replugging it back, you will need to perform rsync-like operations to catchup with server 1.
Is It That Hard ?¶
After reading this short chapter you may wonder what actually are the punch archiving features. Said differently : could you just do the same on your own using servers or a storage bay ?
Maybe, but here is what the punch provides :
- files or blobs saved to archives require metadata and indexing so as to be efficiently retrieved later on. The punch archiving service use elasticsearch to store these metadata.
- Consuming Kafka to write batches of logs to a target archive requires lots of subtle details
- idempotence
- end-to-end acknowledgement
- subtle batch and file naming scheme : per batch per partition and possibly never repeating if combined with write-once storage solutions
- generation of per batch hashes to further provide data integrity guarantee
- state-of-the-art monitoring : whatever be the size of your application from a few hundreds to several tenths of thousands of log per seconds, you need continuous capacity planning
- migration strategies. Updating a platform that contains terabytes of cold data is a difficult exercise.
In short : not that easy.