Spark Primer¶
Abstract
This chapter highlights key concepts that will help you understand what are spark punchline, and why we did it.
Spark¶
Note
Punchlines goal is to let you leverage Spark. Hence understanding Spark first is required. In this short paragraph we provide you with the minimal set of concepts and explanations.
A spark application is in fact a graph of operations. You can code that graph using scala,
python or java APIs.
The punch lets you do that using a configuration file where each operation is referred to
as a node.
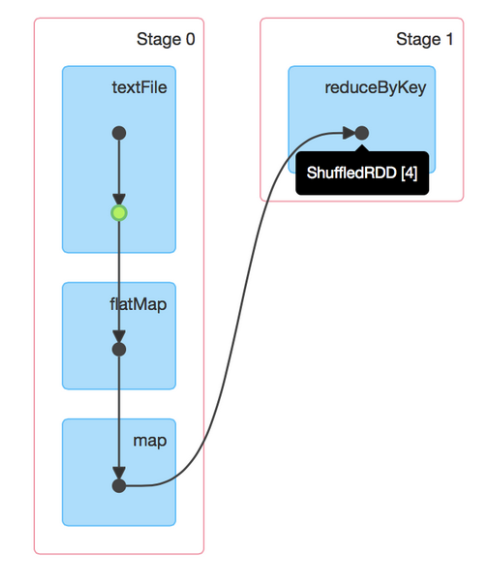
Here is one of the simplest spark job example (courtesy of their documentation) :
Quote
This job performs a simple word count. First, it performs a textFile operation to read an input file, then a flatMap operation to split each line into words, then a map operation to form (word, 1) pairs, then finally a reduceByKey operation to sum the counts for each word.
The blue boxes in the visualization refer to the Spark operation that the user calls in his / her code.
Using a punchline these (blue) operations are defined in the punchline configuration file.
Each operation is called a node.
Another particularly important feature of Spark is the machine learning library : Mllib. The punch provides you with mllib node and stages so that you can benefit from it without coding.
The Mllib apis introduce an additional concept : ML pipeline. A pipeline is (yet another) graph of
operations referred to as pipeline stages. Here is an example:
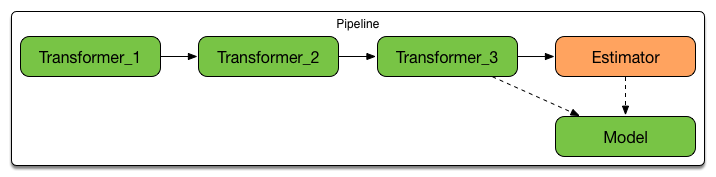
Tip
Typical stages are Estimators, Predictor, Transformers. Even if not clear to you,
just assume for now these
are essential and useful operations you need to combine in order to design machine
learning processings.
Such pipeline can be embedded in a Spark node. To sum up a typical standard machine learning workflow is as follows:
- Loading the data (aka data ingestion)
- Extracting features from that data (aka feature extraction)
- Training model (aka model training)
- Evaluate (or predict)
Spark punchlines introduce no new concept. They simply let you define all that in a single configuration file. Conceptually a punchline job looks like this:
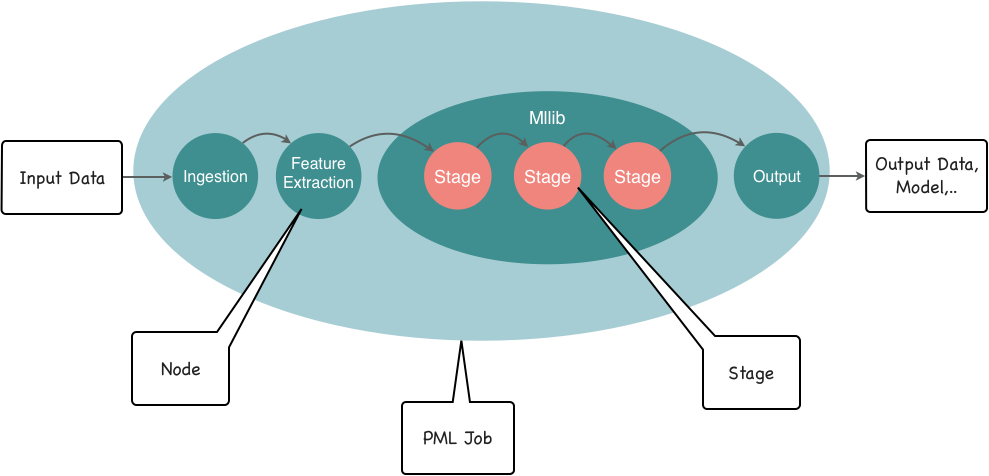
Rationale¶
The PunchPlatform Machine Learning sdk lets you design and run arbitrary spark applications on your platform data.
Why would you do that ? Punch platforms process large quantities of data, parsed, normalized then indexed in Elasticsearch in real time. As a result you have powerful search capabilities through Kibana dashboards. In turn, spark applications let you extract more business values from your data. You can compute statistical indicators, run learn-then-predict or learn-then-detect applications, the scope of application is extremely wide, it all depends on your data.
Why Spark ? For two essential reasons. First it is a de facto standard framework to execute parallel and distributed tasks. Second, because it provides many (many) useful functions that dramatically simplify the coding of application logic. In particular, it provides machine learning libraries. These two reasons makes Spark as the best candidate in terms of simplicity/efficiency trade off, as illustrated next.
Doing that on your own requires some work. First you have to code and build your Spark pipeline application, taking care of lots of configuration issues such as selecting the input and output data sources. Once ready you have to deploy and run it in cycles of train then-detect/predict rounds, on enough real data so that you can evaluate if it's outputs is interesting enough. It is risky to performs such actions on a production environment. Putting at risk its stability is a no-no...
In short : it is not that easy.
The goal of punchlines is to render all that much simpler and safer. In a nutshell, punchlines lets you configure arbitrary spark pipelines. Instead of writing code, you define a few configuration files to select your input and output data, and to fully describe your spark pipeline. You also specify the complete cycle of execution. For example : train on every last day of data, and detect on today's live data.
That's it. You submit that to the platform and it will be scheduled accordingly.
Note
it is very similar to the punch way of exposing Storm topologies as plain configuration files. In turn combined as part of channels.
Benefits¶
Comparing to developing your own Spark applications, one for each of your machine-learning use-case, working with punchline configuration files has key benefits:
- the overall development-deployment-testing process is dramatically speed up.
- once ready, you go production at no additional costs.
- all MLlib algorithms are available to your pipelines, plus the ones provided by thales or third party contributors.
- the new ML features from future spark versions will be available to you as soon as available.
- everything is in configuration, hence safely stored in the PunchPlatform git based configuration manager. No way to mess around or loose your working configurations.
- you use the robust, state-of-the art and extensively used Spark MLlib architecture.
In the following we will go through the punchline configuration files. Make sure you understand enough of the Spark concepts first.
Punchlines versus Plans¶
A spark punchline is a spark application, defined by a json configuration. You can execute a punchline in one of the two modes : cluster or local. Using the local mode, the punchline is started in a local jvm. Try that first. Using the cluster mode, the punchline is submitted to a spark worker node. A first process, called the Driver is launched first. That driver submit in turn so called executor processes.
A plan is basically a punchline iterator. It lets you run periodic punchlines, typically in charge of handling data in between time periods. A plan is composed of a punchline template file and the plan configuration file itself. Together they define how are generated the actual punchlines.
Quick Tour¶
In order to quickly understand and manipulate the punch Machine Learning feature, here is a short description of the approach you have to adopt.
First, install and start standalone.
Once it is started you can open your browser and go to http://localhost:5601 Go to the punch Panel, punchline editor and you will have the list of the node and stage that are accessible through punchlines. Just check the documentation if you want more details about each stage or node and click on execute to test your punchline.
If you prefer going from a terminal, go into the $PUNCHPLATFORM_CONF_DIR and type the
following :
punchlinectl start --punchline $PUNCHPLATFORM_CONF_DIR/samples/punchlines/spark/basics/dataset_generator.hjson
This will execute the dataset_generator.hjson job. Try the
others as well.
Next you can try to submit these example jobs to the spark cluster:
punchlinectl start --spark-master spark://localhost:7077 --deploy-mode client --punchline $PUNCHPLATFORM_CONF_DIR/samples/punchlines/spark/basics/dataset_generator.hjson
This time the job is submitted to the spark master, executed in turn by the spark slave. Have fun !