Archiving Service
An Elasticsearch cluster can store you data, but it requires a large amount of disk to hold the indexed data, which is (typically) fully replicated for resiliency.
The punch archiving service is a cost-effective solution to hold years of data, with a fair level of indexing capability. It provides the following features:
- a secure storage of years of data
- an efficient time-based/data type extraction
- massive and long-running data replay
- multi-locations archiving
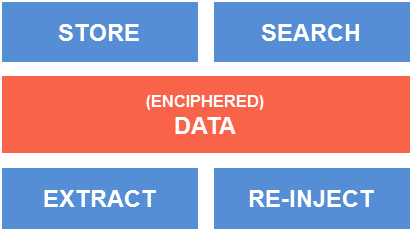
This chapter explains these various topics.
Storage Backends¶
The archiving service runs on top of three backends: the S3 backend, the ceph object storage backend, or a shared filesystem.
Minio S3 Storage¶
Minio is an open-source storage system. It delivers a scalable, high-performance, resilient storage.
To ensure scalability and resiliency, it is distributed on several nodes and works as an object-storage.
Minio is the recommended and provided S3 solution with the punch, but you can actually use any S3 service. We strongly recommend using Minio as it's provided with the punch.
Using the punchplatform you don't need to master the Minio concepts: the PunchPlatform hides the details and exposes a high level view. The Minio cluster is, just like any other components, automatically deployed and monitored. Only its main characteristics must be well understood.
Ceph Object Storage¶
Ceph is an open-source storage system. It delivers a scalable, high-performance, resilient storage, able to aggregate the disk space from multiple linux servers.
To ensure scalability and resiliency, it is distributed on several nodes and can be used as an object-storage (compatible with S3 and Swift APIs), as a block-storage or as a file-system storage.
One of the great features of Ceph is its erasure-coding system. Instead of fully replicating the data to ensure its high availability, it computes an erasure code (similarly to a RAID 5 mode) for each chunk of data. Just like for RAID, the associated CPU and storage overhead depends on your desired resiliency level.
As an example on a 10-nodes cluster, you can decide to accept up to 2 nodes failures with no data loss, with a storage overhead of 25% (10 data chunks instead of 8).
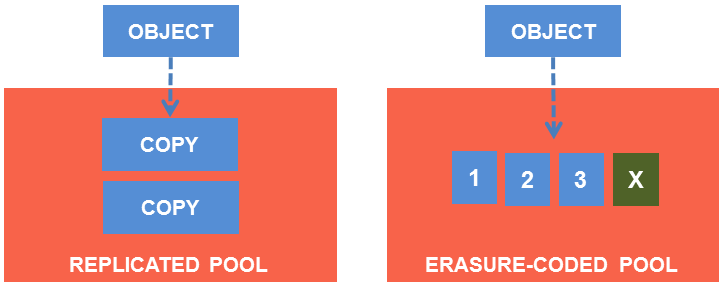
Using the punchplatform you don't need to master the Ceph concepts: the PunchPlatform hides the details and exposes a high level view. The Ceph cluster is, just like any other components, automatically deployed and monitored. Only its main characteristics must be well understood.
Shared Filesystem storage¶
The punch archiving service can also be deployed on top of a posix filesystem. It must then be mounted on all the required cluster nodes.
This can for example be a NFS shared storage, in which case resiliency and scalability must be addressed by the underlying shared storage solution (e.g. RAID mechanism in the storage hardware).
The benefit of using the archiving service instead of writing data to plain files is that you can extract and manage your archive data easily using the punchplatform features (indexing/statistics/automatic purge/replayability). If you write data to files on your own it will be up to you to think of all these details.
Warning
if you use the archiving service, you will be able to manually browse the files. The file organisation and layout is easy to understand. However, there is no guarantee this layout will be compatible with subsequent punchplatform releases. We strongly advocate you stick to the official archiving service tooling.
Elasticsearch for metadata¶
Data is written in batches. Each batch is described by a name, number of logs, number of stored bytes, etc. This set of information is stored into an Elasticsearch cluster. So the punch archiving service needs Ceph (or a shared file-system) and Elasticsearch to work.
This set of information, also named as metadata in this documentation, offers two main features:
- a global overview of you data through Kibana dashboards: you know where is your data, you can compute statistics on specific time-ranges, etc.
- fetching data from your archiving system through specific topologies or CLI.
Each time you will need to inspect or fetch data, you will have to provide an Elasticsearch cluster name, as referenced in you punchplatform.properties.
Advanced Topics¶
Objects Indexation¶
this section is informative. It explains how the data is written and indexed in object mode.
The Objects-storage archive maps some Kafka concepts: data is written in a topic and topics are partitioned.
Data (for examples logs) is written by batches. Each batch is part of a partition. This is illustrated next:

As already said, this metadata is stored in Elasticsearch.
Archiving Service Operations¶
Please refer to Objects Storage Operation Tips section.