Shiva Application Scheduler¶
Overview¶
The punch relies on a simple yet powerful application scheduler called Shiva.
Shiva is a lightweight distributed application manager implemented on top of Kafka. It lets you submit arbitrary applications to some of the nodes of your (punch) cluster.
Shiva is simple and powerful and can be used to enrich a channel with various periodic or long running applications.
Tip
Having shiva gives the punch a tremendously simple yet extremely robust and distributed architecture.
There is no single point of failure, no virtual IP addresses, no complex active-passive scheme, no need for kubernetes or docker or mesos or similar infrastructures to take care of these issues.
Of course the punch is compatible with all these environments, it is just that you do not need them.
Examples¶
Here are some concrete examples where the punch relies on shiva:
Data Collector¶
How do you safely and efficiently transport some data from one site to another ? Go for Kafka data shipping, i.e. transporting your data from one Kafka to another. Here is the idea:
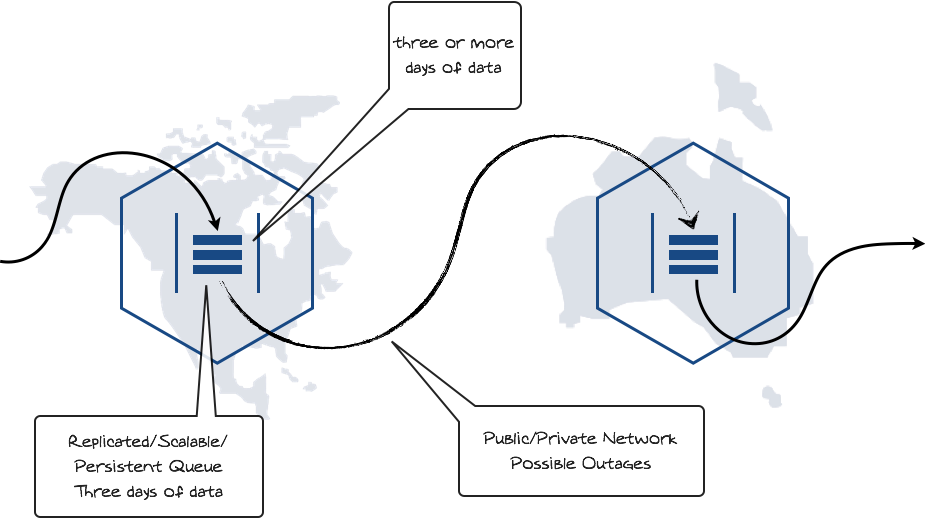
Punch topologies are great for this use case, they can take your data from a Kafka and put it into another one using acknowledged protocol, security and compression. Topologies are executed using the punch lightweight engine.
Platform Monitoring¶
The punchplatform is periodically gathering some metrics to publish the platform components health status as metrics to elasticsearch. Shiva is in charge of periodically executing these applications.
Administrative tasks¶
The punchplatform ships in with ready to use administrative services such as elasticsearch or archiving housekeeping. Shiva is in charge of running these.
Shiva Architecture¶
this chapter is informational
In this chapter we describe the internal shiva architecture.
Shiva is deployed on a number of the platform nodes. Each node is running a tiny java agent, communicating with its peers and sharing information only through Kafka. Refer to this chapter for understanding how this work. No other communication than Kafka is required.
Using shiva you can run long-lived applications such as a Kafka streaming applications, a metricbeat, anything you can think of. You can also run tasks periodically, for example run a data cleaning job in charge of deleting old data from elasticsearch. These tasks are defined as punchplatform services.
To illustrate how shiva works, consider a three server cluster. Each server runs one shiva daemon. As part of a channel you can request a task to run somewhere (i.e. it does not matter if it runs on server1, server2 or server3), you may not care, as long as it runs.
Compared to many other job manager, shiva is lightweight. It has been designed to run on small systems. Yet it can scale to hundreds of servers. It has a second strength : a task can be anything you can think of.
Multi-Tenancy¶
The punchplatform is carefully designed so as to run all administrative or applicative tasks as part of a tenant. The same holds for Shiva and shiva tasks, you cannot submit a task outside the scope of a tenant.
More precisely, shiva tasks must be declared as part of a channel. Examples are:
- Application-level tasks.
- machine learning batch jobs
- kafka stream applications
- external data fetchers
- data aggregator and KPIs indexers
- lightweight topologies
- etc..
- Administrative tasks with a per tenant scope
- elasticsearch housekeeping
- archive service housekeeping
- kafka topic monitoring
Refer to the Channels documentation.
Important
this is an important punch features: stop using crons, scripts manually deployed on servers, virtual ip addresses/failover/active-passive configurations.
You will end up with a spagetthi plate that will be unmanageable and will prevent you to manage and update your platform.
Operation Guide¶
Shiva Cluster Configuration¶
As part of your punch you can deploy one or several shiva cluster(s). One is enough in most cases.
Refer to the deployment guide for details. A shiva cluster consists of shiva agents deployed on each cluster node. They are all associated to a given Kafka cluster.
Each shiva node is associated with tags. These tags allow
you, in turn, to associate an application to one or several shiva nodes.
Application Configuration¶
To define and schedule a shiva application you must simply declare it along with
its inner components as part of the channel applications array.
Here is a self-documented example:
{
"version" : "6.0",
"start_by_tenant" : true,
"stop_by_tenant" : true,
"applications" : [
{
# declare this apps as being a shiva app.
"runtime" : "shiva",
# the short name of the application. The application unique name
# will appear as <tenant>_<channel>_<name>
"name" : "your_task_name",
# the command to launch. It can be your own script or one
# of the punch provided command.
"command" : "your_command",
# the command argument(s). It works using the usual args[]
# parameter settings. The first (args[0]) is the actual
# command to launch. The next ones are parameters.
"args" : [
# each argument has a "type" and a "value" property
# "type" can be "file"
{ "type" : "file" , "value" : "your_task.sh" },
# Here is how you pass in another file argument
{ "type" : "file" , "value" : "conf.yml" }
# you can also pass in strings
# { "type" : "string" , "value" : "hello" }
#
# inline jsons
# { "type" : "json" , "value" : { "timeout" : 10 } }
#
# the special "task_info" type makes your application receive
# a json document filled with the tenant, channel/service name
# and your task name. It is used in many administrative service
# that work in the scope of a particular tenant.
# { "type" : "task_info" }
#
# Your task will then receive a json string like this:
# {"task":"kafka_service","service":"admin","tenant":"mytenant"}
],
# the target shiva cluster name. This name must be associated
# to a shiva cluster defined in your punchplatform.properties
# file
"cluster" : "common",
# the tags to place your task to the shiva node you want.
"shiva_runner_tags" : ["red"]
# an optional cron expression should you require periodic
# scheduling of your task. Here is an example to execute
# it every 30 seconds
#
# "quartzcron_schedule" : "0/30 * * * * ? *"
}
]
}
Example
checkout the sample stormshield_networksecurity channel delivered as part of the standalone platform.
Quartz Scheduler Quick Reference¶
A cron expression is a string comprised of 6 or 7 fields separated by white space. Fields can contain any of the allowed values, along with various combinations of the allowed special characters for that field. The fields are as follows:
Seconds Minutes Hours DayOfMonth Month DayOfWeek Year
10 * * * ? *Fire every 10 seconds0 0 12 * * ?Fire at 12pm (noon) every day0 15 10 ? * *Fire at 10:15am every day0 15 10 * * ?Fire at 10:15am every day0 15 10 * * ? *Fire at 10:15am every day0 15 10 * * ? 2005Fire at 10:15am every day during the year 20050 * 14 * * ?Fire every minute starting at 2pm and ending at 2:59pm, every day0 0/5 14 * * ?Fire every 5 minutes starting at 2pm and ending at 2:55pm, every day0 0/5 14,18 * * ?Fire every 5 minutes starting at 2pm and ending at 2:55pm, AND fire every 5 minutes starting at 6pm and ending at 6:55pm, every day0 0-5 14 * * ?Fire every minute starting at 2pm and ending at 2:05pm, every day0 10,44 14 ? 3 WEFire at 2:10pm and at 2:44pm every Wednesday in the month of March.0 15 10 ? * MON-FRFire at 10:15am every Monday, Tuesday, Wednesday, Thursday and Friday0 15 10 15 * ?Fire at 10:15am on the 15th day of every month0 15 10 L * ?Fire at 10:15am on the last day of every month0 15 10 L-2 * ?Fire at 10:15am on the 2nd-to-last last day of every month0 15 10 ? * 6LFire at 10:15am on the last Friday of every month0 15 10 ? * 6LFire at 10:15am on the last Friday of every month0 15 10 ? * 6L 2002-2005Fire at 10:15am on every last friday of every month during the years 2002, 2003, 2004 and 20050 15 10 ? * 6 #3Fire at 10:15am on the third Friday of every month0 0 12 1/5 * ?Fire at 12pm (noon) every 5 days every month, starting on the first day of the month.0 11 11 11 11 ?Fire every November 11th at 11:11am.
Application Execution¶
To start your applications, simply use the
channelctl command. You can
check the status of application using either the application logging or monitoring as
explained hereafter.
Application Logging¶
Logs generated by applications are automatically intercepted and centralised into Elasticsearch. This makes it easy to monitor the advent and status of your apps.
What shiva does it to intercept all stdout/stderr logs from its child tasks. These are then forwarded to the platform administrative elasticsearch cluster. These logs are also written to the local node shiva log directory, in case you need a direct file access. Note that these log files are rotated and compressed.
Tip
In the shiva logs folder you will find two files. One corresponds to the shiva agent logs,
the other prefixed with 'subprocess' logs all the child apps logs.
Application Monitoring¶
Shiva is extremely simple, the return code of each command is logged as an event to the platform admin elasticsearch. There you can check if they run ok, you can also add an alerting rule to be notified should one of your application fail to execute.
Development¶
Here are a few useful tips should you want to contribute to Shiva development. or simply if you want to play with a Shiva cluster. Make sure you have a standalone installed.
Default Standalone Configuration¶
By default, the standalone will start a Shiva single daemon, both acting as a leader and as a worker. If you start a channel that relies on a Shiva application, the shiva daemon will get the notification to start that application and will start it as you expect.
In order to see the status of the Shiva daemon you can type in:
punchplatform-standalone.sh --status
punchplatform-shiva.sh --status
Tip
Remember that all punchplatform-xxx.sh commands are designed specifically and only for the standalone punch.
Starting Shiva in foreground¶
It may be easier to work with a foreground shiva execution mode, and immediately get the logs in your terminal. Here is how to do that.m Simply stop your Shiva daemon:
punchplatform-shiva.sh --stop
Then restart it using:
punchplatform-shiva.sh --start-foreground
Testing Shiva options¶
You can provide the Shiva options inline. For example in order to name you shiva instance "myLeader" and make it run only as a leader, simply type in:
punchplatform-shiva.sh --start-foreground --leader-only --instance-id myLeader
Running a Shiva Cluster¶
No need to go docker or vagrant. Simply type in in two different terminals the shiva command you want using several configuration files.
java \
-Dlog4j.configurationFile=./log4j2.xml \
-classpath tpunch-shiva-*-jar-with-dependencies.jar \
-c your_shiva.conf
You can very easily run Shiva in your favorite code editor should you want to debug or code new features.
Debugging a Shiva cluster¶
First, Check shiva services
Then, because Shiva uses Kafka topics, check shiva kafka topics