HOWTO configure a topology to write logs in ceph archive
Why do that¶
The first typical use case of PunchPlatform Archiving system is to store a large amount of logs (typically years of logs) for later potential extraction/replay.
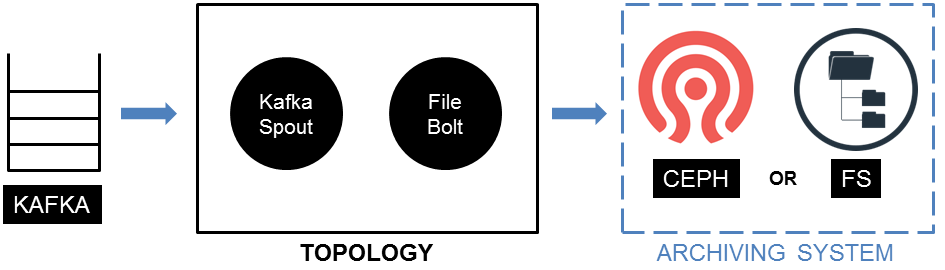
The main idea is to read data from a Kafka broker (which is the usual interface on PunchPlatform) and to write it on an archiving system (a Ceph cluster or a FileSystem - in file-system mode or object-storage mode, it doesn't matter for the moment).
As usual we configure a topology with a Kafka Spout and a File Bolt :
Prerequisites¶
You need a topology injecting data in your Kafka broker. We assume you are be familiar with this.
What to do¶
Suppose we want to inject myTenant data from a Kafka topic myTopic in a Ceph cluster named myCluster, without ciphering. You need a topology with a Kafka spout and a file bolt.
1- Configure your Kafka Spout :
-
Because the file bolt writes batches of data (instead of single logs), your kafka spout has to be configured in
batched<KafkaInput>mode (batch _size > 0). -
Configure batch _size and batch _interval carefully : it sets size of batches, in term of number of events and of duration.
-
Configure the source topic name to myTopic
-
Declare the fields you want to archive (typically log, raw _log, local _uuid and local _timestamp).
2- Configure your FileBolt - Configure the File bolt with the following Bolt_settings
Warning
The pool name you choose must exist in your Ceph cluster. The
pool is not automatically created during channel launching, it
is created during PunchPlatform deployment and must be
explicitly declared (see deployment settings description
3- Start your topology (in foreground or in a real channel)
4- Check archive status by calling a PunchPlatform command<ObjectStorageOperationTips>:
Note
If there is no result, be patient. According to the Kafka Spout batch _size and batch _interval parameters that you defined earlier, you may wait some time before effective writing in archives.
5- Check archived data content by calling another PunchPlatform command<ObjectStorageOperationTips> (adapt from-date and to-date parameters):