Rationale¶
Abstract
To go production with an analytics and/or big data platform, you will need to easily deal with stream processing, batch processing and administrative tasks. The Punch aims at making that simple and easy. This guide provides the rationale of the punch architecture, components and overall design.
Data Processing¶
To reliably process data at high rate, the Punch chains hops, where data goes from one safe place to another. In between two hops, you plug in your processing. By safe, what is meant here is a persistent storage where the data resides long enough so as to be reprocessed in case of failure. Each hop thus is as follows:
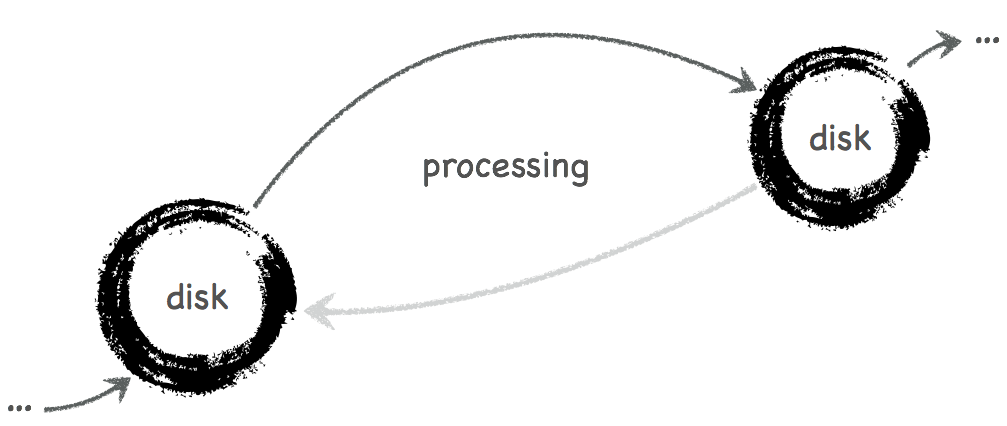
If you are working streaming, this must go fast. The Punch uses Kafka as intermediate storage, it is reliable, extremely fast both for writing to disk and to publish data to consumers.
If you are working batch, you need fast parallel IO to quickly read process then write possibly large amount of data.
In both cases what is required is a runtime platform that can host and run your processing functions, yet be capable of scaling out, survive failures, and detect data losses so as to replay the data. The Punch uses Twitter's Storm and Spark technology, they do provide exactly that.
Info
Dask is planned for integration in the punch to handle scientific data intensive use cases.
Whatever be the technology, note that a complete processing chain generally requires more than one hop. Think of taking the data from (say) equipments up to several destination for (say) indexing, archiving, or performing correlation. Hence, what you get is more like this:
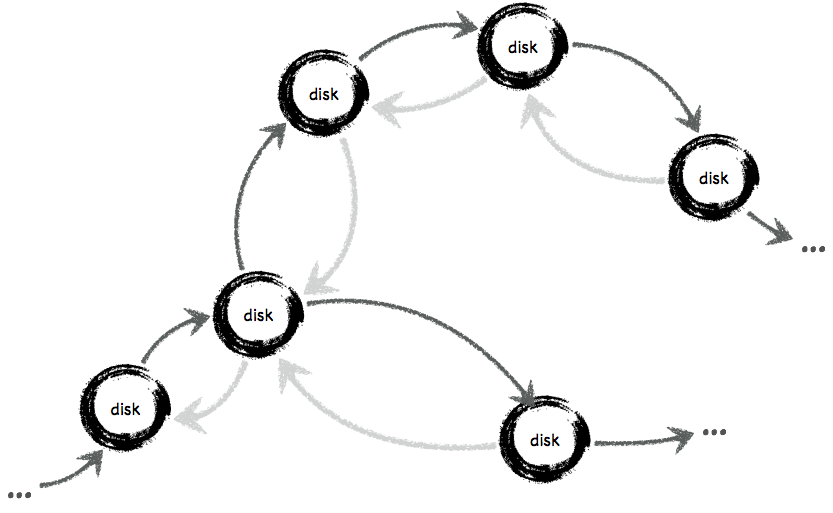
Because each hop is reliable, the chain is eventually reliable. In practice, setting up such processing chain is hard work : from hardware and software configuration, testing, monitoring, up to (hot)-(re)-deploying processings, possibly going through several security zones, or even distant sites. If not carefully designed, the setup just illustrated will turn to be hardly manageable, and will likely not behave as expected.
Hence the Punch. A Punch can act as data emitter, generating events, proxy, running processing on the fly, or receiver, indexing the data in the adequate backend.
Data Stores¶
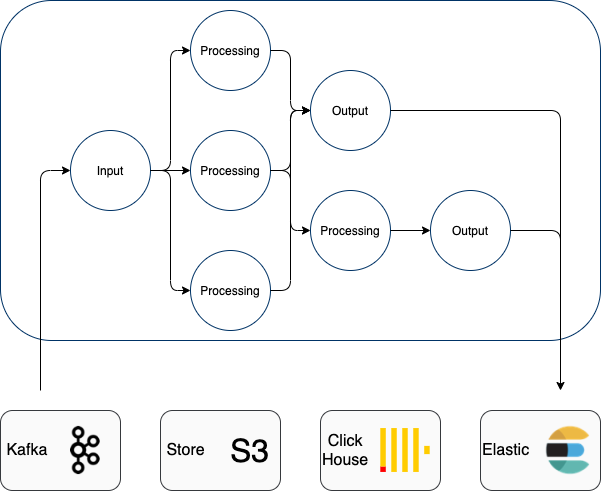
The punch integrate several database or data store engine : Elasticsearch, Clickhouse and S3 Minio. Not to name Kafka, but Kafka is mostly used for temporary storage and orchestration.
Here is a quick view of a typicaly punch application, it reads data from one of these store process it and store the result back in some store.
Punchlines¶
We started this rationale guide with a technological zoo : storm, spark, dask, elasticsearch. Clickhouse, Minio. They provides lots of power and great features, but can be your nightmare if you need to understamnd each, code your application, and deal with platform upgrade.
There come punchlines : whatever your processing is, you represent it on top of the punch as a configuration graph called DAG (Direct Acyclic Graph). Have a look at the punchlines overview.
Technically speaking, a punchline is a either a storm topology, a Spark job (stream or batch) or a punch enabled lightweigth topology. The latter is a lightweigth single-process DAG. Functionally, each is doing something useful on your data (parse, enrich, train, learn, detect).
The benefits of using punchlines are as follows :
- you can assemble your processing apps without coding, simply by using off the shelves Punch functions. They are many.
- using the punch language you can code lots of simple or complex processing functions. A log parser is a typical example.
- You have no dependencies to low level (spark|elastic|clickhouse|S3) API.
- If you need to, you can add your own processing nodes. These can be java or python. and the dependency management is taken care for you.
- One year later you will upgrade your complete punch with a new release. You will then truly understand the benefits of this per-configuration approach. Upgrades become easy, not requiring service interruption nor recoding of your apps.
Channels¶
In real life an application does not consists in a single punchline. You may need to combine several ones as part of a consistent overall (bigger) set.
This is where channels come into play.
A channel consists of an arbitrary number of hops, each taking the data from a (reliable) queue to another up to some backend. Each hop runs your processing, or simply transport your data to the next destination. Channels are high-performant, scalable, reliable but also monitored. Starting/stopping/reloading a channel is straightforward, whatever be the actual complexity of the underlying channel structure.
Info
Customers onften manage several platform, for example two platforms can be deployed on two distant sites for geo-replication setup. Or to deal with log collection from many sites to a central one. Channels, however, are defined and managed in the scope of a single platform.
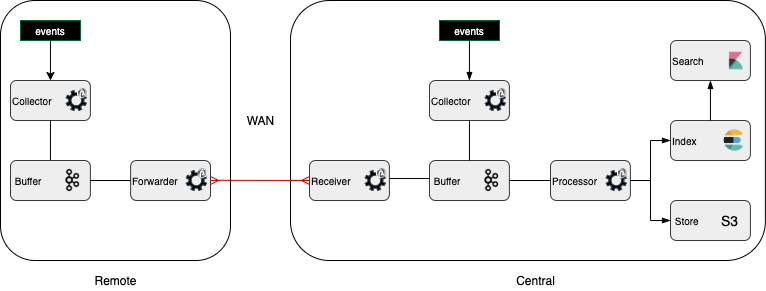
Concretely, let us illustrate a real use case. Logs are collected from some equipments at some site, they must be transported to several destinations on several sites, to end up being processed in several backends, (say) several Elasticsearch clusters, for log analysis and forensic, and to a QRadar correlation engine, installed on one of the site. The PunchPlatform makes it possible (and easy) to setup a complete transport and processing chain to take care of:
- log transport using scalable and reliable guarantees
- log transformation,
Parsing, enrichment, filtering, duplication - log indexing, (short and long term) storage
- visualization and forensic using Kibana dashboards
- log forwarding to third party tools such as QRadar
All in all this is synthesized next:
A Closer Look at Punchlines¶
Input Connectors¶
Data enters a platform through input connectors. These comes as Storm spouts, deployed inside Storm topologies, and acting as a platform data entry point.
The PunchPlatform supports Kafka, file, TCP/UDP/SSL sockets to consume input data. Connectors can be easily added to the platform whenever needed.
!!! note "On TCP sockets, the PunchPlatform accepts the Lumberjack acknowledged protocol. That makes it possible to ingest data from elastic beats or logstash forwarders, and provide reliability from the start."
Output Connectors¶
Data can be saved to Kafka, Elasticsearch, Ceph, or to a socket peer. Using the acknowledged syslog protocol just cited, you can chain several platforms yet benefit from end to end reliability. More precisely, if the destination platform suffers from a failure, the lost data will not be acknowledged, and will be replayed until it eventually is processed and acknowledged.
Processing Functions¶
In many real-time streaming big data applications, processing is actually simple : performing regex based pattern matching, transforming the data using key value or cvs like operators, filtering/pruning the data, computing aggregations, etc ... Even so, only a programming language has the required expressiveness.
Storm is Java centric. Besides the language, the API is subtle and low level. We want our users to express their document transformation using a much simpler and JSON friendly programming language. The PunchPlatform brings in a programming language : Punch, that makes working with JSON document as simple as possible. An example of punch, here is how you add nested properties in a JSON document :
{
[user][name] = “bob”;
[user][age] = 24;
}
The Punch language has many characteristics that makes it very compact, and easy to work with. Users actually deploy Punchlets as part of their channels, in just minutes. Punchlets are small Punch programs deployed, compiled and executed on the fly. Punchlets give the platform administrators complete control over the documents:
- timestamping, versioning, enrich the data in arbitrary ways
- filtering/pruning the data
- running regular expressions, key-value or CSV formatting and many more operators
- detect and/or generate various kind of events, from the content of the data going through or from accumulated information.
- routing the data to Elasticsearch indexes, backends, other Punchlets hops.
- ...
Punchlets are designed for Storm : a punchlet can generate documents, in one or several Storm data streams so as to be consumed by downstream Storm components.
Tip
If you are familiar with Logstash, Punchlets will be very familiar to you. All the Logstash regexes patterns are available to punchlets. In fact, the PunchPlatform, as for log processing is concerned, is Logstash on Storm steroids.
This said, in some cases you may require to code using a standard programming language, and benefit from powerful editors. The PunchPlatform lets you code in Java and provides a Java API to let you benefit from all the Punch language goodies. For you to understand here is the same example than above but written in Java:
root.get("user").get("name").set("bob");
root.get("user").get("age").set(24);
As you can see, it is not far being as compact.
Searching Your Data¶
Our vision is to let you benefit from Kibana and Elasticsearch capabilities, not restricting their use. You will find a great amount of online and public resources to help you design the dashboards you need. Both the Elasticsearch and Kibana communities are extremely active, and keep adding features and delivering improvements or bug fixes. We designed the PunchPlatform so as to be extremely easily upgraded to new versions, without service interruption or data loss.
The following is a very basic Kibana dashboard, providing a quick view of a set of log parsers. That level of dashboard is what you start from, using a standalone PunchPlatform package.
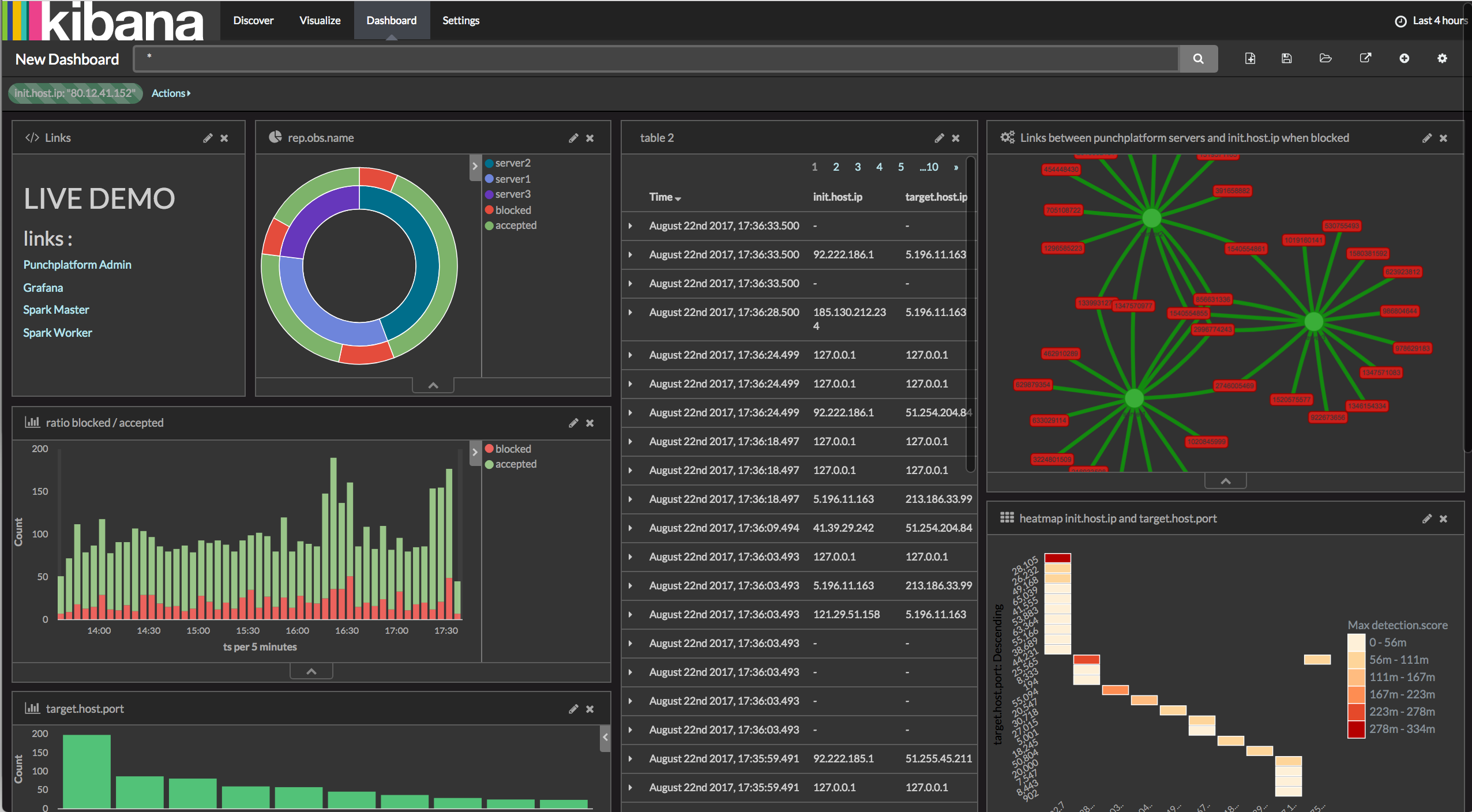
Tip
the data highlighted here was processed using the standard log parsers delivered as part of the platform. It was injected using the PunchPlatform injector. All that is available to you in minutes.
Operations¶
Running a big-data streaming platform requires state-of-the art supervision capabilities. Standard supervision tools, collecting metrics every now and then, cannot scale up to follow the events rate. The PunchPlatform ships with a supervision chain capable of dealing with high throughput metric collection. Not only these metrics are stored, you also benefit from a Kibana graphical user interface, that you can customize in the way you need.
After installing a punchplatform (i.e. after a few minutes), you start with a complete platform level supervision plane and ready-to-use dashboards.
You can further easily define your application level monitoring using ready-to-use metrics generated by all punchplatform components centralised in an elasticsearch instance.
The PunchPlatform publishes many useful metrics. Some of them lets you keep an eye on the traversal time of your data in your data channel. The principle, illustrated next, consists in injecting monitoring payloads in the data streams, in a way to collect information along their journey. Each traversed hop publishes in real time the corresponding information so as to let you visualize how the data is traversing the complete chain:
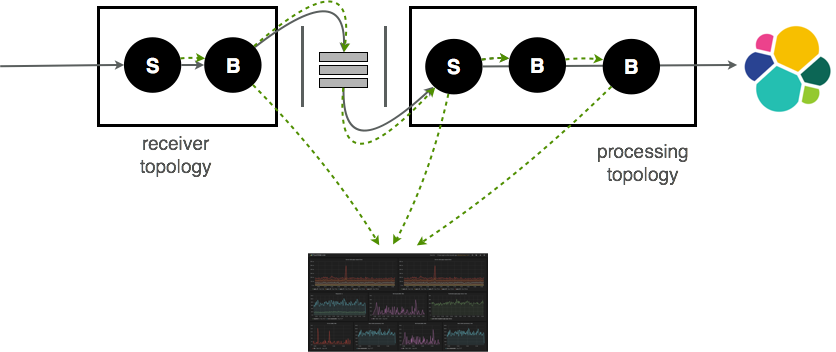
This scheme works also using a proxying scheme, so that you can visualize and monitor information coming from a remote PunchPlatforms, running on a different system, typically used as a data collector and forwarder system. This is illustrated next:
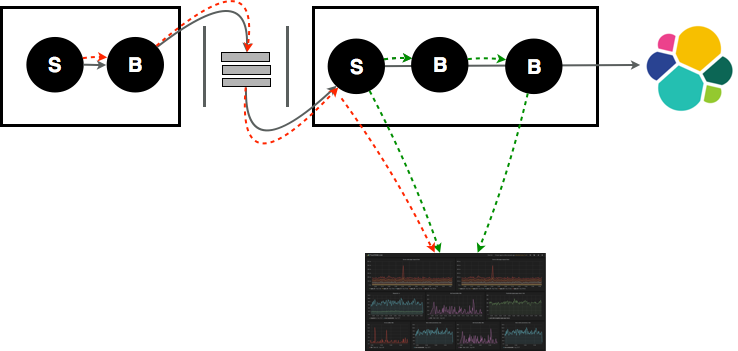
Important events must be detected in real-time, so as to immediately trigger the generation of new, aggregated events. The PunchPlatform offers many ways to implement alerting. The PunchPlatform components publish many useful metrics to standard metrics receivers. These receivers can then perform their own alerting using various strategies and calculations.
The PunchPlatform always publish metrics in a way to scale. It performs real time statistical analysis on the fly and only publish consolidated metrics so that it works whatever the traffic load is.
The PunchPlatform publishes metrics at various levels : platform, tenant, channel, module. Besides, punchlets can publish their own metrics or alerts. For example to track the usage of a particular string sub-pattern in a log field, to react to a timed occurrence of some value, or to immediately notify the administrator of dropped traffic.
Footprints¶
The PunchPlatform can endorse several roles. Parts of your channel can be implemented using small Java processes, only in charge of forwarding logs to the first Kafka hops, yet executing a punchlet to take care of a first transformation. The following illustrates the memory occupation of a forwarder topology. It runs using a 128Mb RAM settings, and processes 5000 logs/seconds. Garbage collection occupation is under 1% of the overall CPU usage.
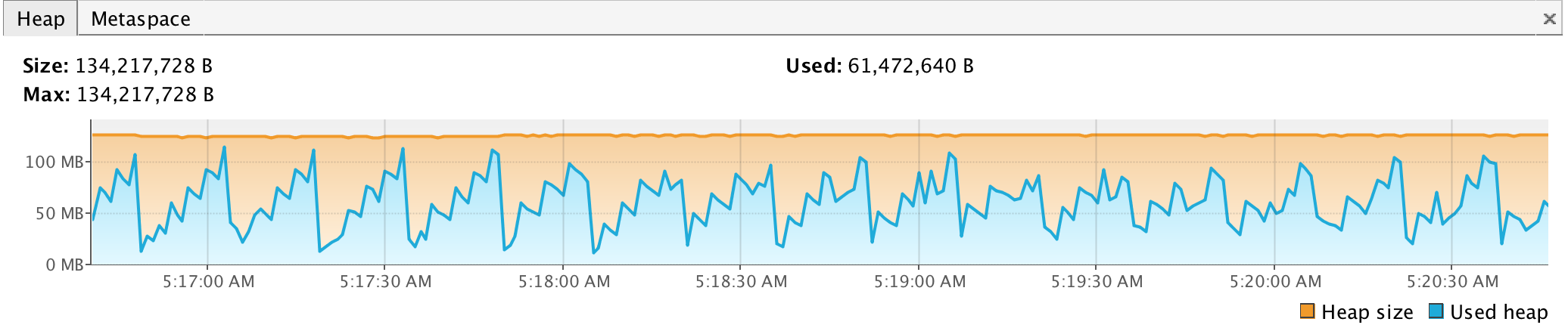
In contrast, other part of the channel may consist in bigger Java processes for performing aggregation. They will need more RAM to store intermediate computations.
The point is : both logics can be part of a single channel. The PunchPlatform provides a smart Storm scheduler so as to place the right components at the right locations in your cluster of machines. You can dedicate servers to ingesting data, in a dedicated security zone, with small machines (in terms of RAM), while submitting data intensive treatments to another partition of your servers, where you use more powerful machine.
Summary¶
With just a few Punch lines of code, you can invent your topologies, scaling up to your needs, and covering a large set of use cases : parsing, enrichment, normalization, filtering, machine learning. Although the PunchPlatform has been initially designed to cover the log management use case, it is great for any high performance textual data processing.
Because Kafka Storm and Spark are designed for simplicity, scalability and reliability, you have little limits . The real value of the PunchPlatform is to let you benefit from these great technologies in minutes, not days or weeks, and be immediately ready to run and manage a production environment.
Our vision is to let you benefit from Kibana and Elasticsearch capabilities, not to restrict their use. You will find a great amount of online and public resources to help you design the dashboards you need. Both the Elasticsearch and Kibana communities are extremely active, and keep adding features and delivering improvements or bug fixes.
We designed the PunchPlatform so as to be extremely easily upgraded to new versions, without service interruption or data loss.